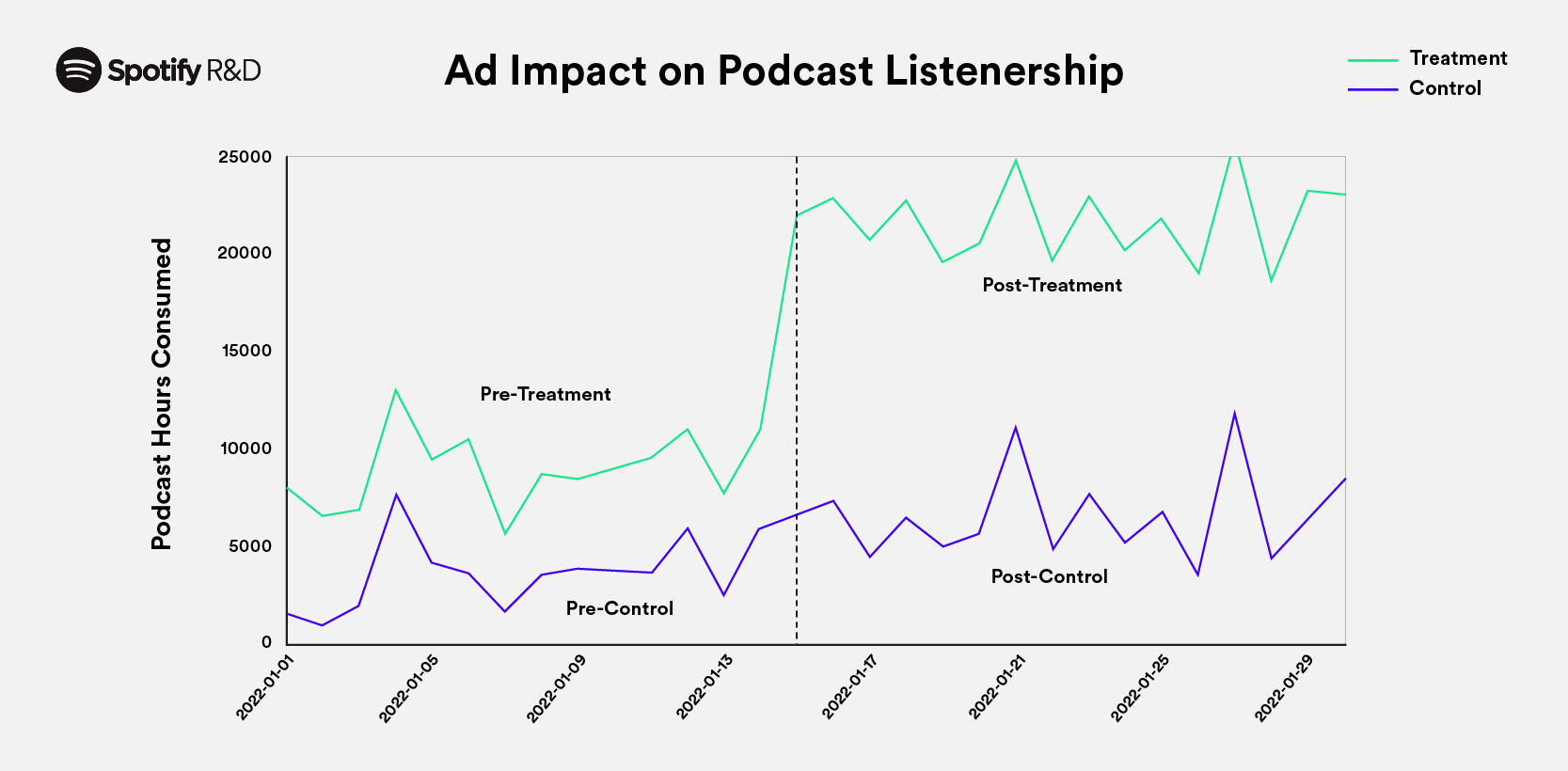
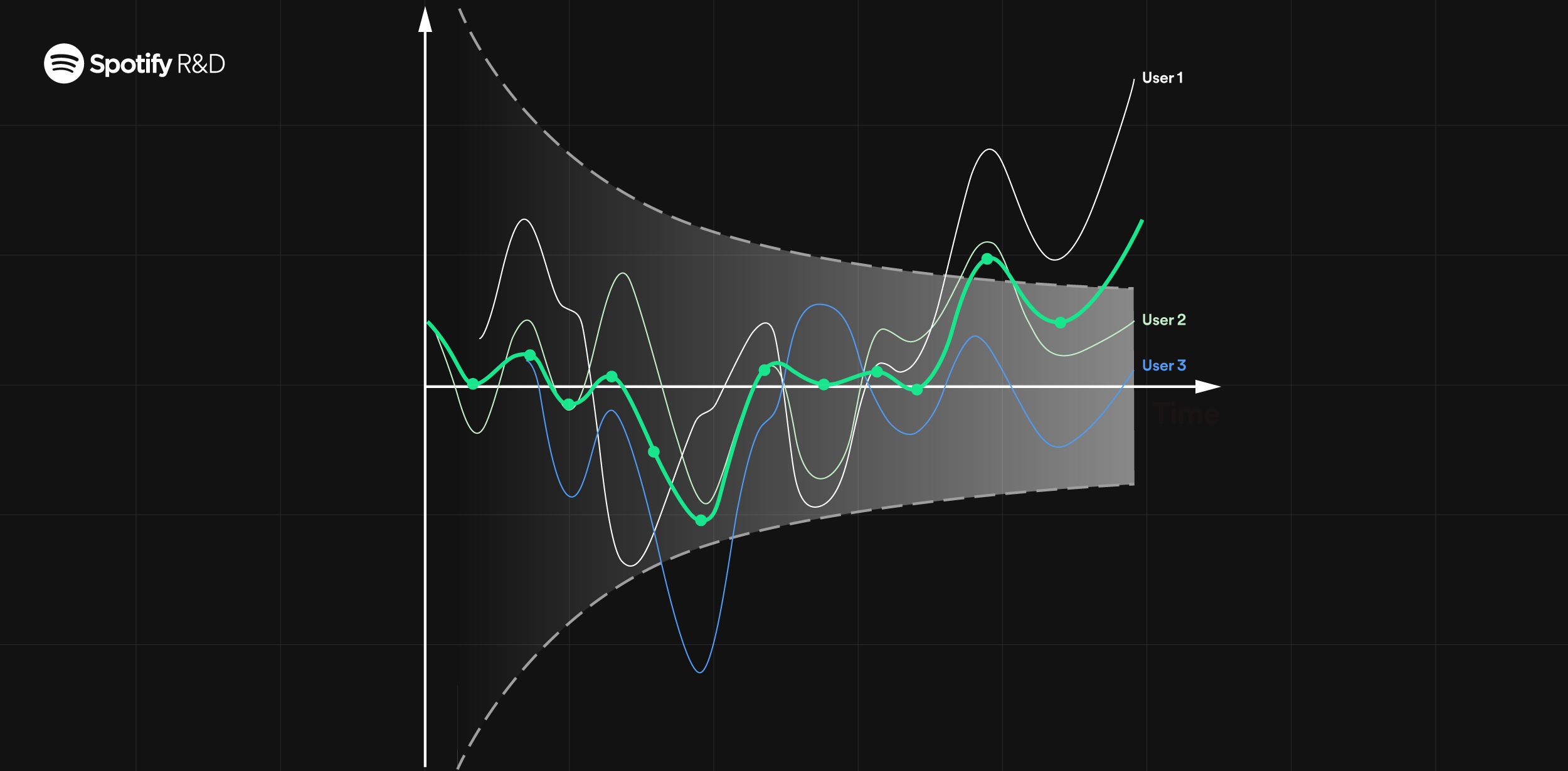
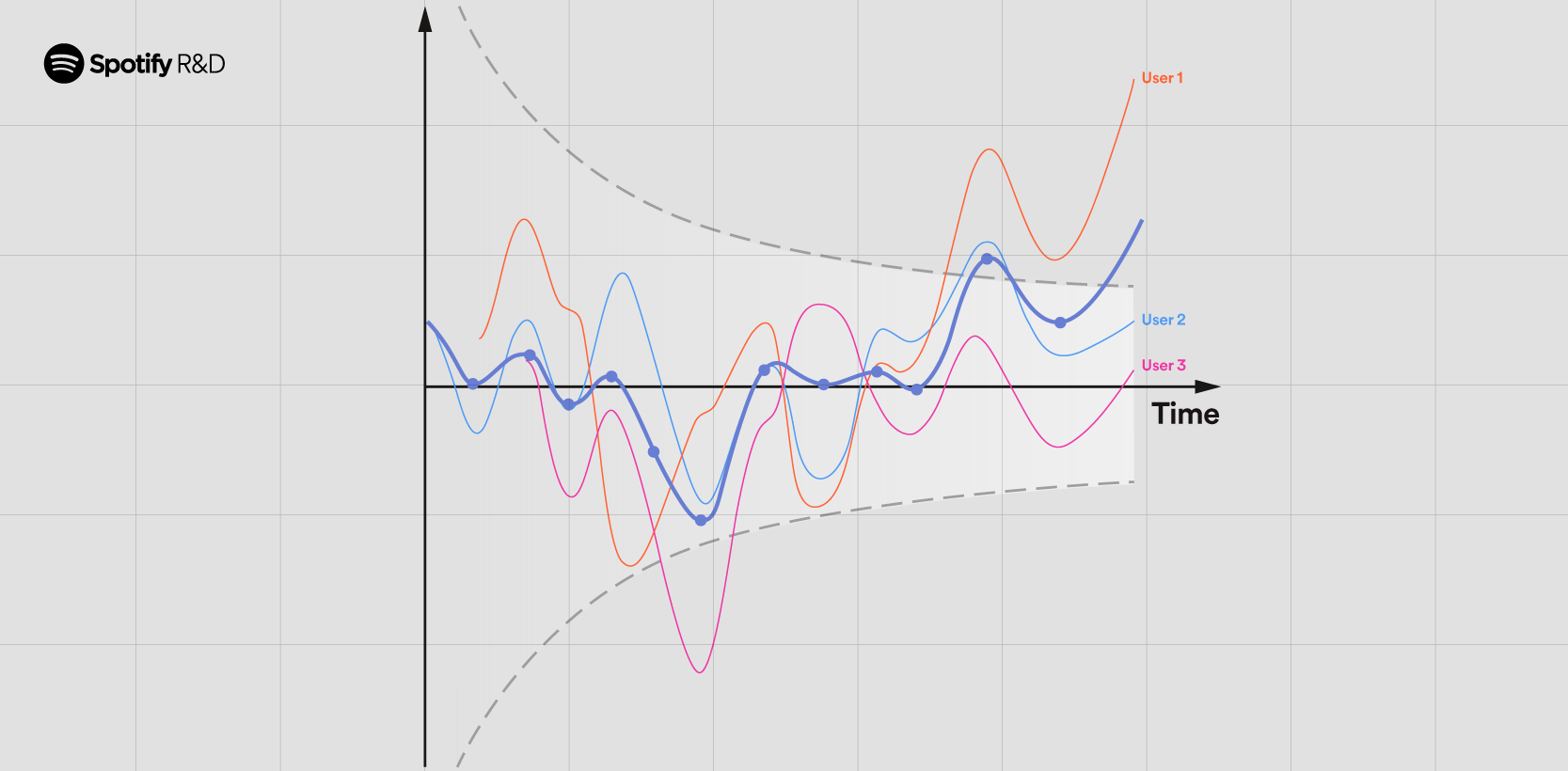
April 2, 2024
Read about the magic behind the music & more.
Welcome to our official technology blog.
As engineers working at Spotify, we frequently find ourselves explaining our robust data platform to fellow professionals who are contemplating [...]


](https://storage.googleapis.com/production-eng/1/2024/01/EN212-FOSS-Fund-2023-QA_QA-1200x590_v2.png)


](https://storage.googleapis.com/production-eng/1/2023/10/EN201_FOSSFund23Winners_blog-post_Op-2symmetrical-1200x-590.png)
](https://storage.googleapis.com/production-eng/1/2023/10/EN205_Kelsey_ngn_1200x590.png)