How Spotify Scales Apache Storm
Spotify has built several real-time pipelines using Apache Storm for use cases like ad targeting, music recommendation, and data visualization. Each of these real-time pipelines have Apache Storm wired to different systems like Kafka, Cassandra, Zookeeper, and other sources and sinks. Building applications for over 50 million active users globally requires perpetual thinking about scalability to ensure high availability and good system performance.
Thinking Scalability
Scalability is the ability of the software to keep up the performance even under increasing load by adding resources linearly. But achieving scalability requires more than just adding resources and tuning performance. To achieve scalability one needs to think holistically about software design, quality, maintainability and performance aspects. When we build applications we think about scalability in the following way:
Necessary conditions for Scalability
- Software has sound architecture and high quality
- Software is easy to release, monitor and tweak.
- Software performance can keep up with additional load by adding resources linearly.
Scalability in Storm
So what does scaling Storm pipelines entail? I’ll work through an example of our real-time personalization Storm pipeline to elaborate different aspects of scalability.
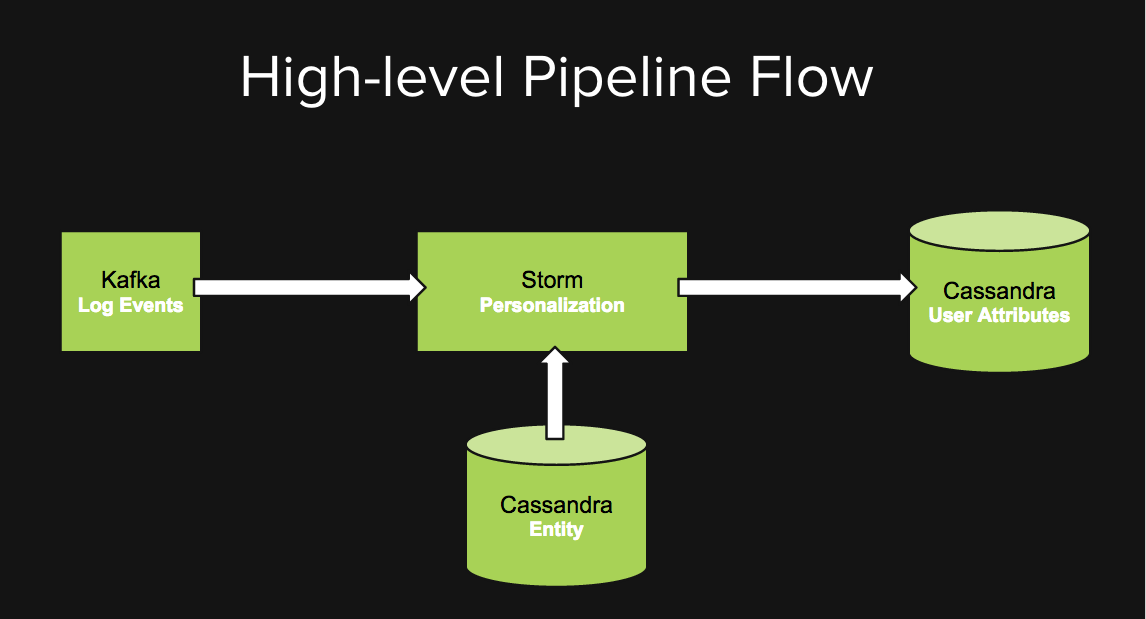
In our personalization pipeline we have a Kafka cluster with topics for different kinds of events like song completion and ad impressions. Our personalization Storm topology subscribes to different user events, decorates the event with entity metadata (like genre of a song) which is read from Cassandra, then groups the events per user and computes different user attributes by some algorithmic combination of aggregation and derivation. These user attributes then get written to Cassandra which in turn gets called by several backend services to personalize user experience.
Design and Quality
When we added new features to our personalization pipeline over time our topologies started to look very complicated for performance tuning and event flow debugging. However having high test coverage gave us the confidence in the quality of our code to rapidly refactor the topologies and make them tenable.
Topology Architecture
Undergoing the whole cycle of transforming a complex topology to small maintainable topologies taught us the following lessons:
- Create small logical topologies for different workflows
- Promote reusability of code via shared libraries as opposed to shared topologies
- Ensure methods are easily testable
- Parallelize and batch slow IO operations
Quality
We’ve developed our pipelines in Java and we use JUnit to test the business logic in different computational Bolts. We’ve also created end-to-end tests by cluster simulation using the backtype.storm.testing dependency.
Maintainability
To easily rollout the software to new hosts in our cluster and monitor its health here are few things that we did to ease maintainability.
Configuration
Externalizing all the tunable parameters gave us the ability to tweak the software without changing the code. It makes it easy to make small incremental changes and observe the effects. We’ve externalized values for bolt parallelism, source endpoints, sink endpoints, and other topology performance parameters in a config file.
Metrics Visualization
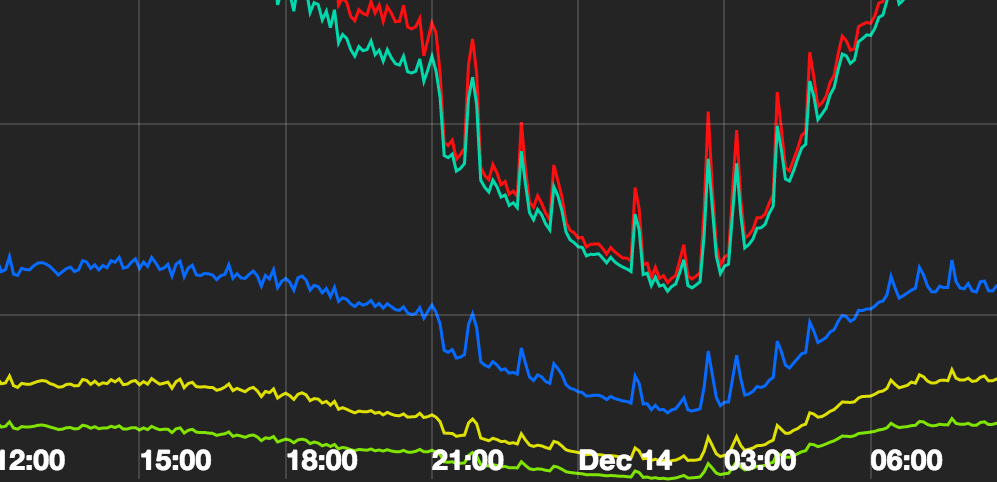
We maintain a dashboard of our topology metrics to evaluate it’s health in a glance and also troubleshoot problems. We’ve made sure we have very high level metrics (see below) to summarize the general health of the system since it’s very easy to get lost in a dashboard full of metrics and not know which one is really important.

Topology deployment

All the computations in our personalization pipeline are idempotent and we’ve designed our deployment strategy to ensure we don’t lose any messages during deployment by allowing a little bit of duplication in event processing. This strategy won’t work for everyone especially if their computations are transactional. In the diagram above events are chronologically arranged from left to right and t1…t8 are different timestamps.
In our deployment strategy we require our Storm cluster to have enough capacity to run 2 personalization topologies concurrently. At t1 the cluster is running version v1 of the personalization topology. When we are ready to release version v2 of the personalization topology, we build and submit v2 to the cluster. At t4 our cluster is running both the versions concurrently. Each topology uses a unique value for the Kafka consumer groupId, to ensure all of the messages on the topic are delivered to both versions. At this time messages are getting processed twice, but that is fine since the computations are idempotent. At t5 we deactivate v1 at which point it stops consuming events from Kafka. We then monitor the graphs for v2 and ensure all metrics look fine. If things are fine we kill v1 and at t8 the cluster is running only v2. However, at t7 if the graphs look problematic we activate v1 and it resumes consuming events from kafka from where it had left off. We also kill v2 and this essentially is our rollback strategy. Having a safe rollback strategy enables us to rollout small frequent changes and minimize risks.
Monitoring and Alerts
We monitor metrics for the cluster, topology, sources, sinks and set alerts for top level metrics to avoid redundant alarms else it can easily cause alert fatigue.
Performance
Over time we’ve observed different bottlenecks and failures in our system and tuned several things to get the desired performance. Getting the right performance also requires the right choice of hardware.
Hardware
We started off by running our topologies in a shared Storm cluster but over time we hit a resource bottleneck due to resource starvation caused by busy topologies. So we spun up an independent Storm cluster, which was fairly easy. Our current cluster processes over 3 billion events per day. It has 6 hosts with 24 cores, 2 threads per core and 32 GB of memory. Even with this small cluster we are getting great mileage and we are nowhere close to our max utilization despite running 2 versions of the personalization topology concurrently during deployment. In the future we are considering running Storm on YARN on our Hadoop cluster for even better resource utilization and elastic scaling.
Throughput and Latency
To get the desired throughput and latency we had to tune source and sink parameters. We also tweaked a few other things like caching, parallelism and concurrency which are detailed below.
Source and Sink Tuning
Kafka Tuning
- We configured rebalancing.max.tries to minimize regular rebalancing errors in Kafka.
- Use a different group id for each KafkaSpout in each version to ensure redundant message processing during deployment of new topology versions.
Cassandra Tuning
- Different tables for different TTLs. Also set gc_grace_period=0 to effectively disable read repairs for rows set with TTL since we don’t need them.
- Used DateTieredCompactionStrategy for short lived data.
- Control the number of open connections from Storm topology to Cassandra.
- Configure Snitch to ensure proper call routing.
Concurrency Issues
The OutputCollector in Storm is not thread-safe and cannot be safely accessed from multiple threads, such as a callback attached to a Future for asynchronous processing. We use a java.util.concurrent.ConcurrentLinkedQueue to safely store calls to ack/emit Storm tuples and flush them at the beginning of the execute method in a bolt.
Parallelism Tuning
We took inspiration from Strata 2014 Storm talk and tuned the parallelism in our topologies. The following guideline works really well for us:
- 1 worker per node per topology
- 1 executor per core for CPU bound tasks
- 1-10 executors per core for IO bound tasks
- Compute total parallelism possible and distribute it amongst slow and fast tasks. High parallelism for slow tasks, low for fast tasks.
Caching for Bolts
To maintain state for user attribute computation in Bolts we had to choose between external and in-memory caching. We preferred in-memory caching since external caching would have resulted in network IO, additional latency and adding another point of failure. However with in-memory caching we don’t have any persistence and limited memory. We didn’t care so much about persistence so we only had to work with memory constraints. We chose Guava’s Expirable Cache, where we could define limits on the number of elements and staleness to control the size of the cache. This enabled us to optimally utilize memory within our cluster.
Taking a holistic approach to scaling Storm pipelines has helped us add more features for our ever growing active user-base while continuing to deliver high availability for our Storm pipelines with ease.
Tags: big data, cassandra, kafka, performance, realtime, scalability, storm, topology




