Monitoring at Spotify: Introducing Heroic
This is the second part in a series about Monitoring at Spotify. In the previous post I discussed our history of operational monitoring. In this part I’ll be presenting Heroic, our scalable time series database which is now free software.
Heroic is our in-house time series database. We built it to address the challenges we were facing with near real-time data collection and presentation at scale. At the core are two key pieces of technology are Cassandra, and Elasticsearch. Cassandra acts as the primary means of storage with Elasticsearch being used to index all data. We currently operate over 200 Cassandra nodes in several clusters across the world serving over 50 million distinct time series.
We are aware Elasticsearch has a bad reputation for data safety, so we guard against total failures by having the ability to completely rebuild the index rapidly from our data pipeline or Cassandra.
A key feature of Heroic is global federation. Multiple clusters can be operated independently and are capable of delegating queries to each other to form a global interface. The failure of one zone will only cause data hosted in that zone to become unavailable. Clusters can be operated across zones to provide better availability.

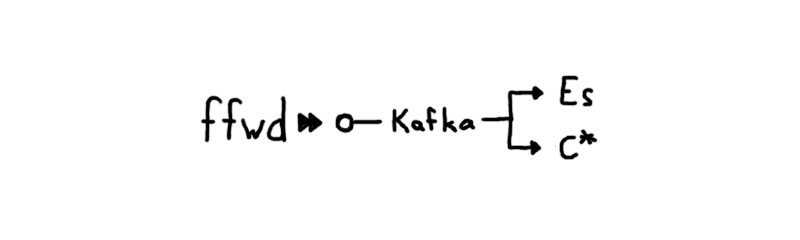
Every host in our infrastructure is running ffwd, which is an agent responsible for receiving and forwarding metrics. The process exporting metrics is responsible for sending them into the agent. This enables our engineers to easily instrument anything running on one of our hosts. A library can safely assume that an agent is available on the host and require close to no configuration. The proximity of the agent mitigates the impact of badly written clients since latency is minimal. The collected metrics are fed by ffwd into a Kafka cluster per zone.
This setup allows us to rapidly experiment with our service topology. Kafka provides a buffer that gives us breathing room in case either Cassandra or Elasticsearch is having a bad day. Every component can be scaled up or down on demand.
In the backend everything is stored exactly as it was provided to the agent. If any downsampling is required, it is performed before the agent by using libraries such as Dropwizard metrics. Engineers can perform extra aggregations over the stored data through the Heroic API. But we rely on a reasonable sampling density from the agent. It’s typically one sample per time series every 30 seconds or more. This approach avoids the delays and complexity which are typically associated with a top-heavy processing pipeline.
In using Heroic, we’ve been able to build custom dashboards and alerting systems that make use of the same interface. It allows us to define alerts based on graphs within the same UI, making it easy for engineers to set up. But Riemann is not going away anytime soon. We find value in having a second method to monitor certain parts of our infrastructure. The long term intent is still to transition more towards visual alerting.
All parts of Heroic is now free software, feel free to grab the code on Github. Documentation and information about the project can be found on the official project site.

Tags: monitoring, open source software, technology




