SDN Internet Router – Part 2
Introduction
In the previous post we talked about how the Internet finds its way to reach content and users; how Internet relations work and what we do to make sure we can deliver music to you. We also introduced some of the technical and economical challenges that come with peering.
In this post we will elaborate on the initial problem we were trying to solve, the challenges we encountered on the way and how we solved them.
Initial Challenges
As we mentioned in our previous post, being present at various locations across the globe and trying to connect to as many subscriber networks as possible has some interesting challenges. The Internet, by the end of 2015, had more than 585,000 routes. In order to accommodate these routes and to be able to route traffic at the speed a service like ours requires, you need very specific equipment. However, this equipment has some drawbacks as they are:
- Very power hungry. 12.000W per device or 33W per 10G port.
- Big. 10 rack units for 288 ports.
- Expensive. List price can be around half a million U.S. dollars.
If you want to be present in several places around the world, you are going to need at each location at least one or two of those big, power hungry and expensive devices. Which is not good given their price tag, power consumption and size. So, why would we do it given these challenges? Being closer to users means that the service works faster and better and we want our users to have the best possible user experience.
Global Architecture
Today, we have 4 big data centers in a few locations:
- London, U.K.
- Stockholm, Sweden
- Ashburn (VA), U.S.
- San Jose (CA), U.S.
We are also present in a few IXPs:
- DEC-IX (Frankfurt, Germany)
- Netnod (Stockholm, Sweden)
- EQIX-ASH (Ashburn VA, U.S.)
- AMSIX (Amsterdam, Netherlands)
- LINX (London, U.K.)
When a Spotify client connects to the service, a combination of techniques is used to make sure that the connection is made to the best possible data center. As we connect to several other organisations’ networks we need to know which of those connections are suitable to reach the connecting client.
A key observation here is that since we already split traffic between datacenters, our networking hardware only needs to know about the networks that are located relatively closely. A router or switch in Sweden probably don’t need to know need to know which network path would be the most efficient to an end user in California.
Hypothesis
Given our global architecture we determined we could try to analyse our traffic patterns and figure out which Internet routes we needed for each particular location. At the time we started working on this project a typical switch had the following characteristics:
- Could support ~32.000 routes.
- As small as a rack unit.
- 72 x 10G ports.
- 262 W
- ~ 30.000 U.S. dollars
Note: More modern switches based on newer chipsets are even better for this particular use case as they support hundreds of thousands of routes respectively for a similar price.
The hypothesis we wanted to prove was that by analysing our traffic patterns we could lower the amount of prefixes up to the point where we could fit them into a switch. If we could prove it we could use a switch instead of a router and save a lot of money.
Stage 1 – Proving the hypothesis
At this point we started looking into proving that “by analysing our traffic patterns we could lower the amount of prefixes up to the point where we could fit them into a switch”. To do that we started using pmacct which is a very interesting open source project for traffic accounting. With this tool we could analyse our traffic patterns by combining sFlow information with BGP prefixes. In addition, to help us to understand our traffic patterns we started developing what would evolve over time into the SDN Internet Router (SIR). This early version would allow us to run some simulations and see what would happen if we would limit our number of routes.
We ran our analysis in each location independently and our hypothesis proved to be correct.
Stage 2 – Designing the prototype
At this point we started talking with several vendors and discussing ideas for how to best program the switch with only the routes we wanted.
- We started looking into solving the problem by programming the switch with OpenFlow. At that time the OpenFlow version you could find in most switches was OpenFlow 1.1, although the OpenFlow 1.3 specification was already available. However, OpenFlow proved to be a) too complex for a prototype and b) a limiting factor as switches usually install OpenFlow entries in the TCAM, which is a very limited memory structure.
- Selective Route Download (SRD) is a BGP feature that allows you to keep all of your BGP prefixes in the user space and choose a subset of them to be installed in the kernel. It was widely supported by most vendors and it was as easy to leverage on as building a prefix-list with the desired routes. For simplicity and scalability we decided to follow this path.
So, after deciding to leverage on SRD the solution looked like this:

- A transit provider would provide a default route as fallback in case something went wrong. Under normal circumstances we wouldn’t send any traffic via this path.
- Our peers would send their own prefixes.
- BGP and sFlow information would be sent by the Internet switch to the BGP controller. The BGP controller would run pmacct to combine sFlow and BGP information and SIR to do some analysis, select the BGP prefixes we wanted and instruct SRD to install that particular subset of BGP prefixes.
Stage 3 – Choosing a switch
Now it was the time for choosing a particular switch to test. After checking our options and talking with several vendors we decided that we wanted a device model that:
- Was backed by a vendor that wanted to be involved in this project to make sure their device performed as expected under this “unusual workload” for a switch.
- Was open; we would build the solution as generic as possible so we could move to another device or even change vendor if necessary.
- Was cost-effective and with a few 100G ports.
- Had some API to be able to easily program the device from an external application.
Finally we decided to go with a vendor which builds its network operating system on top of Linux, allowing to replace some parts of the system with some others if necessary. The vendor also had some tweaks in their drivers to be able to increase the amount of prefixes they could support in the device and they had other tweaks coming to allow even more.
Stage 4 – Building the prototype
Here is where all the fun started; we had an hypothesis, a design for a prototype and a vendor that was open to help us to make sure we would succeed. But things are never easy, are they?
Stripping out parts of the network Operating System
Of course, when plans meet reality things are never that easy. One initial roadblock was a lack of Selective Route Download support on the switch we picked. To work around this problem we replaced the vendor provided BGP implementation with bird, an open source project that implemented the features we needed. We encountered some problems where the routes we tried to install did not get picked up properly by the hardware. This was a problem that the vendor could help us with a patch in less than 24 hours.
Stage 5 – Refactoring the prototype
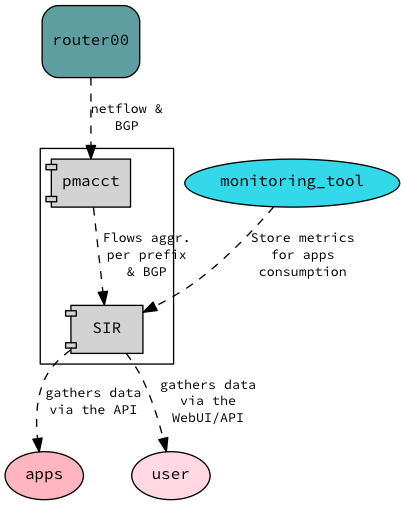
While our vendor was still working on their BGP implementation we started refactoring the prototype to have nicer code that we could maintain easily and that would allow us to do more interesting stuff. After some thinking we decided that SIR would be a smart front end for pmacct where we would expose peering and traffic information via an API so we could write applications on top of it. At this particular point two applications came to mind:
- Peering management reports. Where are we sending our traffic and via who. This would allows to plan better where to peer and who to peer with.
- Route optimisation. This would be the initial use case where we would pick only the routes we needed.
So with this in mind we redesigned our solution. The arrows indicates the direction of the information flow:

Stage 6 – Testing the BGP implementation of our vendor
At the same time we were refactoring SIR we got the new BGP implementation from our vendor so we started testing it.
Here be dragons
In order to test their BGP implementation with SRD support we wrote a tool that I called “Super Smash BroGP”. This tool would pretend to be a device running BGP but it would fake BGP prefixes with random BGP attributes. In addition, it would start to withdraw prefixes and add new ones at random intervals. The idea was to stress test their BGP implementation and see how many prefixes we could keep in the user space and how reliable it was.
As a result, we killed the system; memory leaks triggered under obscure circumstances and internal data structures consumed too much memory. We showed these issues to our vendor and luckily their response was something like ‘we are aware and we were actually doing a major overhaul of our BGP implementation that will solve both issues’.
We were testing bleeding edge code as they were coding so these things happen. They knew and they were working on it so nothing to worry about.
Enlarge your prefix list
SRD relies on prefix lists to select which prefixes you want to install in the hardware. The main problem was that our prefix lists were going to contain tens of thousands of entries. This entailed several challenges:
- Inserting a prefix list with 10.000 entries into the system would take around 10 minutes. This was due to the system doing some sanity checks to prevent mistakes from users.
- Because the prefix list was so large showing the configuration on the screen would take a few minutes. Not a big deal when everything is automated but as this was still in alpha stages we still wanted humans to be able to pet and troubleshoot the device.
- For our operations we rely on the system reporting a diff of the actual configuration of the device with the proposed configuration of the device. Having a configuration with gazillions of lines triggered some internal safeties they had in place.
After discussing with them these problems we designed a solution where they would remove the sanity checks (which reduced the process of inserting the prefix list to a couple of seconds). In addition, they would build a way to install prefix lists via a file or URL so they wouldn’t show the prefix-list in the configuration but just the pointer.
Stage 7 – Going Live
We finally got an image that fixed all the issues we faced; no more memory leaks, we could fit 1.2 million prefixes in the user space, installing prefix lists was fast and we only had a pointer in the configuration instead of hundreds of thousands of lines so we decided to go Live.
We tested the solution in several IXPs like DEC-IX and LINX first and then we deployed it as well in the rest of the locations. The results were astonishing. Everything worked better than expected; we could peer with everybody in those locations, even with the route server without being afraid of overflowing the hardware and without having to buy a big ass and expensive router.
Results
We have been running SIR for a few months in several locations and we are deploying more. Below you can find a table with some numbers:
| IXP | Routes installed | Routes not installed |
|---|---|---|
| LINX | 18672 | 95711 |
| DECIX | 12518 | 108164 |
| EQIX-ASH | 27687 | 75146 |
As you can see we are well within the limits even with the current generation of hardware. With the new generation of hardware we will not need even to filter out any prefix in locations with less than half a million of prefixes.
Conclusion
SIR did not only enable us to peer in several locations without having to spend money on very expensive equipment, we got also other benefits. The API that SIR provides has proven to be useful for figuring out where to send users to in order to improve latency, where and who to peer with and improve our global routing. It also gave us some vendor independence. Although we are using some interesting tweaks from our current platform and we don’t plan to change anytime soon, SIR is compatible with any platform that supports sflow and SRD.
In addition, it’s been a very interesting journey where we got to work and share ideas with very intelligent engineers across different organisations. We also go to separate hype from reality; just because everybody talks about OpenFlow it doesn’t mean is the right tool for the job.
Future
As we hinted at before, soon there will be new switches on the market that will allow us to have almost the full routing table. This doesn’t mean that SIR has no longer a purpose. That means that we will be able to focus on implementing features into SIR that add value to the business instead of working around hardware constraints. For example, we could monitor available paths, choose the best one based on real time metrics and better reporting for peering purposes and capacity planning.
Do you want to peer with us? Check our details in peeringdb. Or perhaps you want to join us and build interesting stuff. And if you are interested in trying out SIR, it’s open source! You can find it on github.




