Commoditizing Music Machine Learning : Services
Five years ago, music personalization at Spotify was a tiny team. The team read papers, developed models, wrote data pipelines and built services. Today personalization involves multiple teams in New York, Boston & Stockholm producing datasets, feature engineering and serving up products to users. Features like Discover Weekly and Release Radar are but the tip of a huge personalization iceberg.
One thing we have noticed is the overhead of running services. Services are easy to launch but have a very real impact on a team’s ability to innovate and build new features. Especially because Spotify has a “you build it, you own it” engineering culture.
Product development starts from the perspective of an end user and drives engineering effort from there on. For example, consider the Discover Page, a portal for all things music personal and new to you. A team would get together, spec the design of the page, figure out what sort of machine learning goes into it, build the models and then get into the product. If it does well, we would ship it. Now, the team has a service to maintain and a maybe a few people worry about things like being on-call.
Flash forward a few months ahead, there is a second ask: Radio — a perfectly reasonable addition to a music product. It also provides a good way of providing feedback to your models. Something that ensures that all that fancy machine learning is not driving blind. A similar routine of product development takes place and the team ends up owning another feature and another service.
This is what happened to that one tiny machine learning team. We owned the Discover Page & Radio. We would process training data, build latent factor models. In other words, we built vectors for every musical entity and user in Spotify. The vectors were stored and manipulated in data pipelines using Sparkey and Annoy. The end-to-end pipeline was stitched together using Luigi & Scalding. The output would be a set of recommendations which would be served up to users from a very simple service that was backed by Cassandra and written using Apollo.
Soon we grew. Spotify acquired a music intelligence company, the Echo Nest. Now there were multiple teams producing data; multiple teams developing personalization features. The amount of thought per pixel was going up. We were shipping richer and better personalized sets. Discover Weekly, the new Start Page and innovations around new users all came from this effort.
Now we faced a couple of new challenges. Teams would intuitively reach for the building blocks they were most familiar with when developing new algorithms. We needed to separate the ingredients from the recipes, better understand their limits. We also needed to ensure that the user’s personalized experience was consistent across Spotify. While there are different facets and flavors to our creations, they all should get you. Music is an emotional experience. If you tell Spotify, that you hate a song on Radio, we have to use that information when we cook up your next Discover Weekly.
Technically we decided to solve these two challenges by building a similarity infrastructure. A platform that would enable teams to learn from each other and for us to enable consistent feedback across all personalization. Unfortunately, a platform of generic machine learning algorithms is easy to over complicate and easier to satisfy none of your users. So we started small. We took a model that powers parts of Discover Weekly. This was being used in services powering playlist recommendations on the Start Page, new user personalization on the Start page and Discover page. In terms of backend services, this would mean unifying three systems, three on-call services, several thousand lines of code.
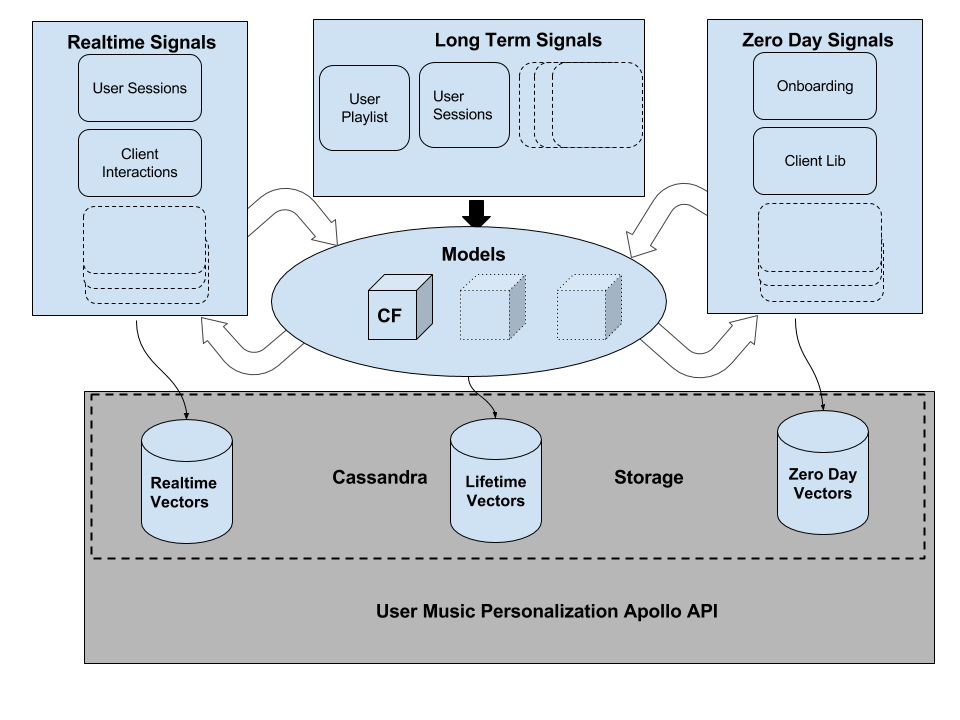
Our API was simple, user centric and opinionated. Any service would be able to talk to us and get musical facts about a user based on their life in Spotify. We also wanted to enable the ability to unlock instant realtime reactions to user behavior.
An interesting technical challenge with implications in both machine learning and systems engineering now arose. Vectors are much more versatile and easier to combine than recommendations. We needed to design our service oriented architecture to manipulate vectors and build recommendations as a last mile effort.
Our models were typically trained on a snapshot of training data to musical entity vectors. We had to modify them so that we could separate the process of generating user vectors from the training step. Depending on the amount of information we needed about the user, we could either build lifetime vectors in a MapReduce pipeline or realtime vectors in Storm. We needed to guarantee that the transaction of generating musical vectors and making them available to all of the processing engines was atomic and consistent. We built an orchestration process, a doorman. The job of this process was to ensure that output of a particular snapshot of training data was atomically updated across the entire system.

We are currently extending the system by adding other models, generalizing it further by adding different signals. This system has enabled us to reduce the complexity of end services. It has also enabled us to disseminate machine learning models built by one team across to multiple other teams. We have quite a few new challenges coming up. How do we translate and move a lot of this infrastructure to our new Google Cloud based ecosystem? How do we build a consistent framework for feedback that enables it to be propagated across several models distributed across several teams? This will involve both systems work and modifying the machine learning models themselves. If you would like to work on this exciting cross section of Infrastructure & Machine Learning, please drop us a line. We are hiring!
Tags: architecture, backend services, big data, machine learning, map reduce




