Reliable export of Cloud Pub/Sub streams to Cloud Storage
Every day, Spotify users are generating more than 100 billion events. Every event is being generated as a response to an user action; listening to a song, clicking on an ad or subscribing to a playlist. All in all, we currently have more than 300 different event types being generated from Spotify clients.
Once delivered, events are processed by numerous data jobs currently running in Spotify. There are many different use cases for which the delivered data is used. Data can be used to produce music recommendations, analyse our A/B tests or analyse our client crashes. Most importantly, delivered data is used to calculate royalties which are paid to artists based on generated streams.
All of the generated events are being collected and delivered by Spotify’s Event Delivery system. To accommodate for different needs which different data jobs might have, events are being delivered to a variety of storage implementations. They are being delivered to Cloud Storage (GCS), BigQuery (BQ), Hadoop (HDFS) and Hive. We’re using GCS as primary storage of our data.
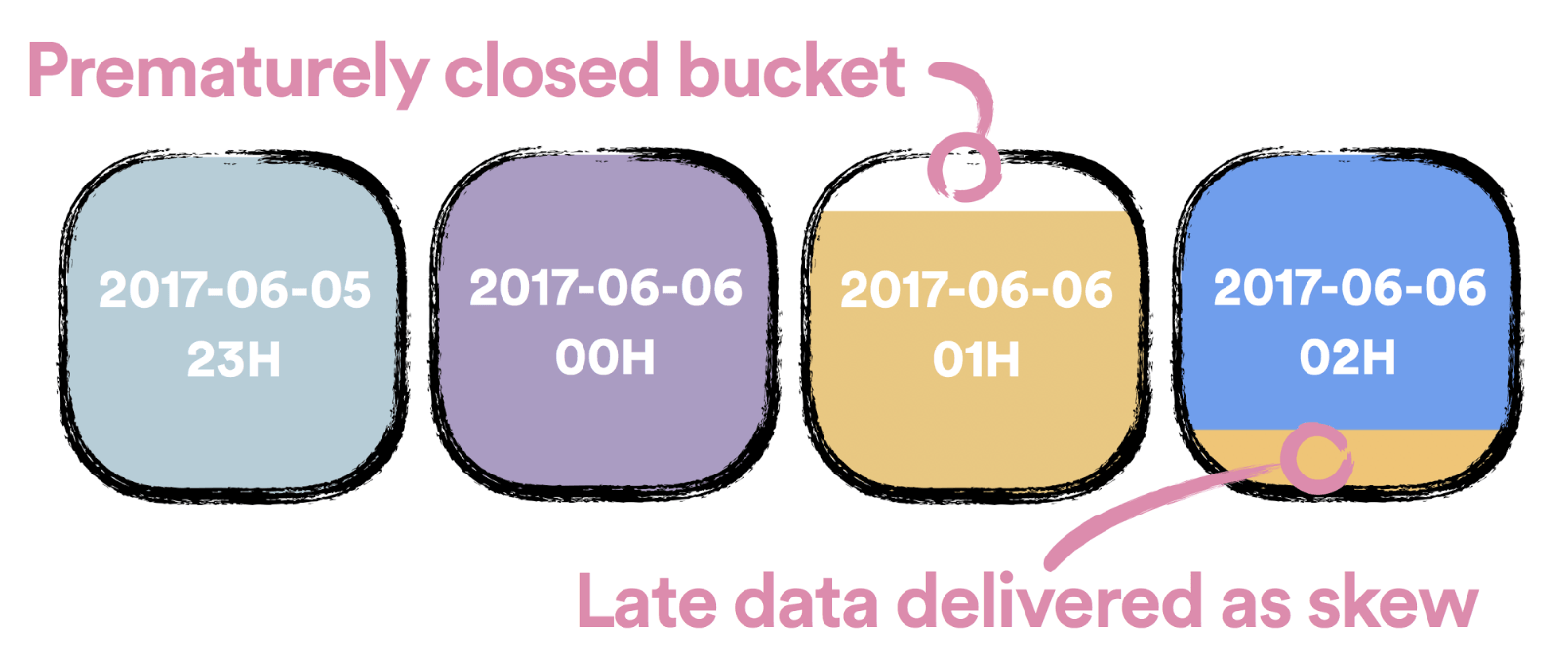
No matter where the events are being delivered, they need to be deduplicated and timely delivered to hourly buckets. In the case of GCS and Hadoop an hourly bucket is represented as a folder, in the case of BQ it’s represented as a table and in the case of Hive it’s represented as a table partition.
Every delivered hourly bucket of data—referred to as a closed bucket—is immutable. This design decision was made to ensure consistency of consumed data across all data jobs no matter when they are executed. In case data arrives late we need to have a graceful way of handling it. Incoming late events are written to hourly buckets which are pending to be closed. We refer to this events as skewed events.
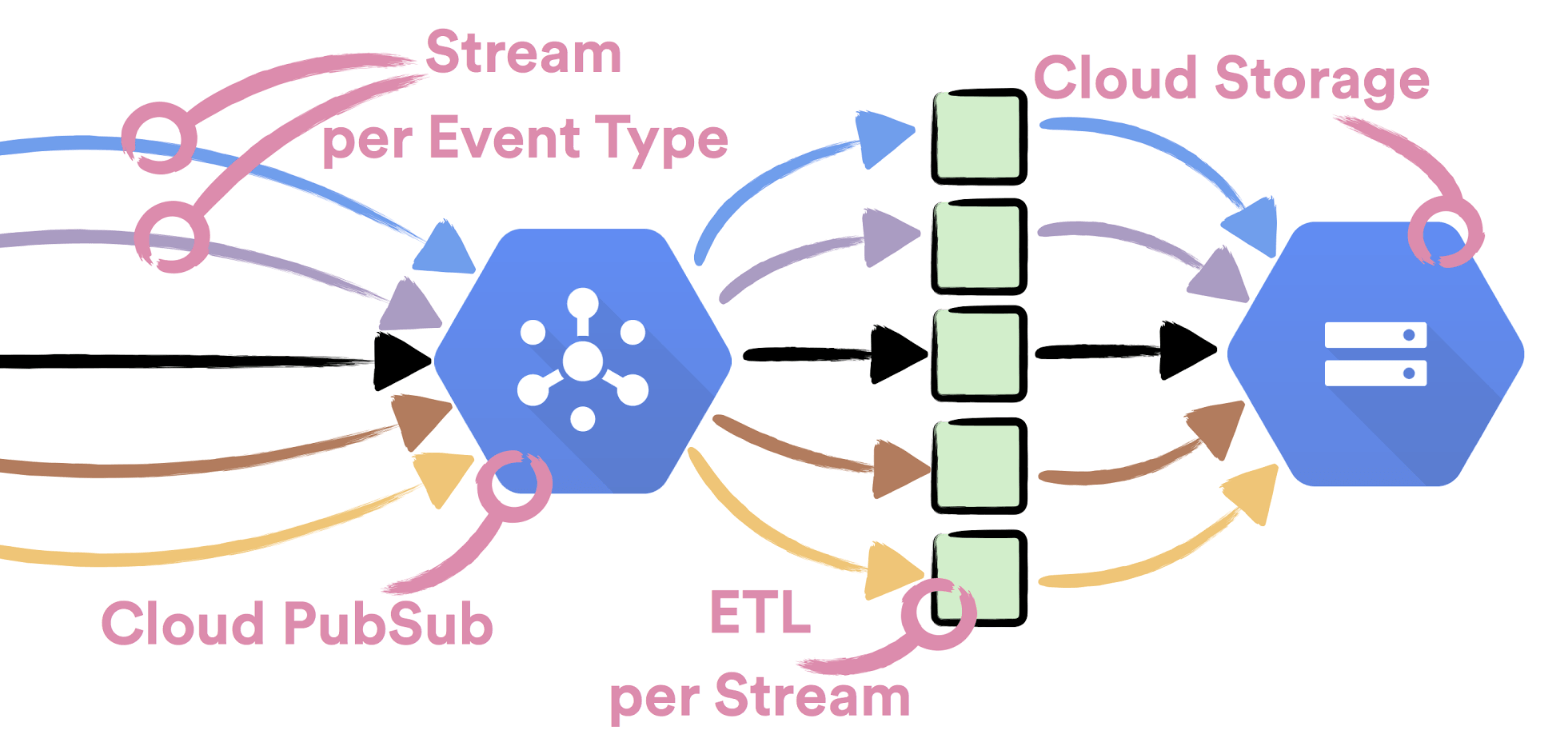
In the first phase of event delivery, all events are published to Cloud Pub/Sub. For easy monitoring and operations of the system, every event type is published to its own dedicated topic. If you’re interested in learning more on how this part of system looks like and what were the reasons to use Cloud Pub/Sub, you can find more details here.
In the second phase of event delivery, all events need to be consumed from Cloud Pub/Sub streams. When consumed they need to be grouped to hourly buckets, deduplicated and delivered to Cloud Storage. We decided to have a dedicated Extract Transform Load (ETL) process for consuming data from each event type stream. The reasoning behind this decision was that we wanted to achieve complete isolation between different event types, so we could scale easily with the growing number of event types and have a simpler ETL logic.
Our first choice for implementing the ETL process was Dataflow. It was our first choice since it’s a fully managed data processing tool which can window stream data based on event time. We quickly wrote a proof of concept pipeline, as described here. However, it turned out that writing the logic to consume the data is just half of the story. Other half is ensuring that system can be reliably operated.
Good monitoring and deployments are crucial for reliably operating systems. For deploying Dataflow jobs we need to use Dataflow API, which is designed to deploy a single job. In order to reliably deploy more than 300 jobs in one go we would need to spend our time in building a reliable deployment process using the existing API. For monitoring running Dataflow jobs the only available tool is Dataflow UI. Using the UI we were not able to determine if all the executing jobs were running the same version nor be alerted if any of our jobs was struggling to process incoming data.
To mitigate operational shortcomings of Dataflow we decided to build the ETL process as a set of micro services and batch jobs. During the years Spotify accumulated experience and developed tools which make operating services and managing batch jobs easy. Many work hours went into making this tools reliable and we didn’t want to spend our time reinventing them for managing Dataflow jobs.
Handling streams reliably is a complex problem. In order to solve it we sliced it into smaller subproblems:
- Reliably consuming data from Cloud Pub/Sub
- Detecting when hourly bucket of data is safe to close
- Deduplicating hourly buckets of data
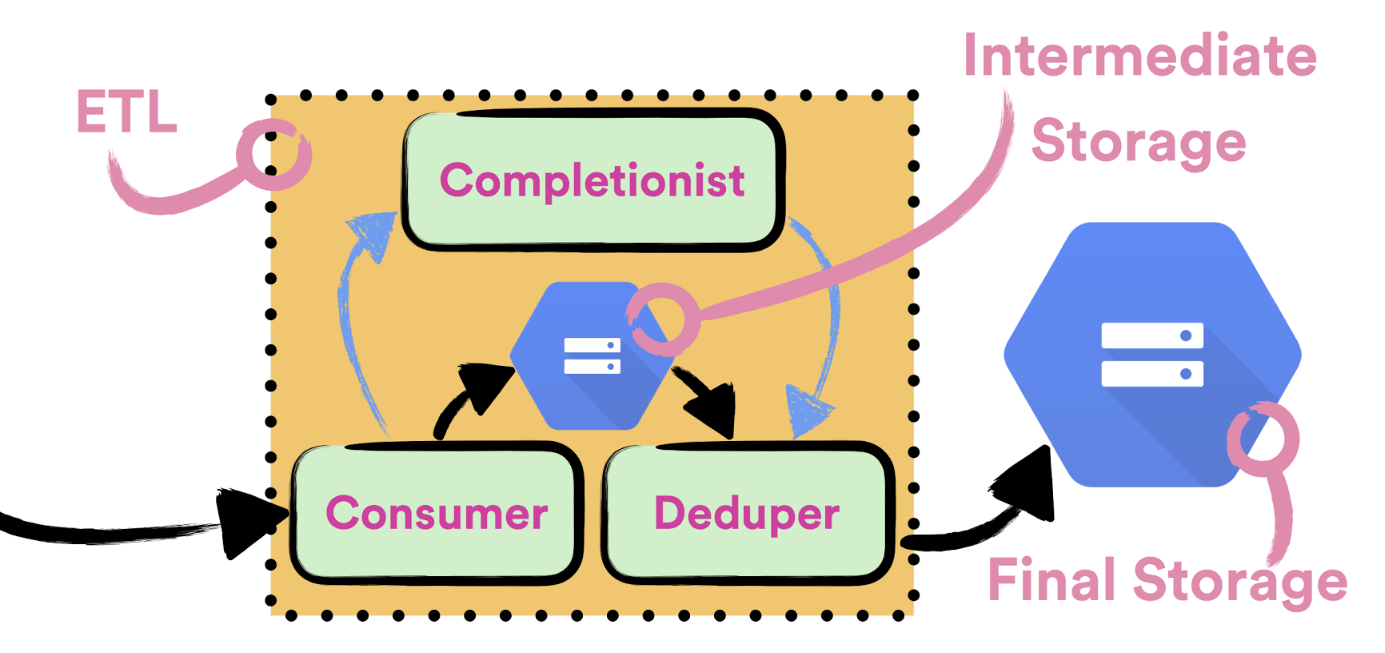
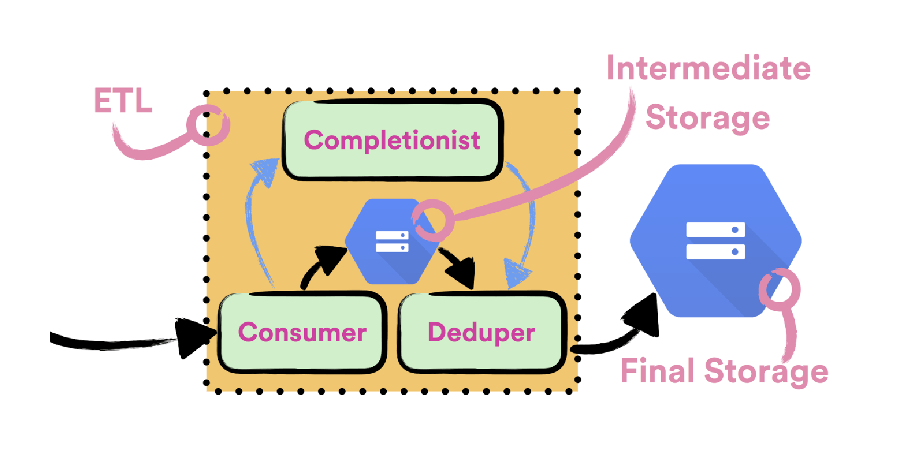
To reliably consume data from Pub/Sub streams we wrote Consumer, a simple Apollo service which is deployed with Helios. A single Consumer instance is responsible for consuming data from a single event type stream. Consumer doesn’t have any notion of hourly buckets and it doesn’t perform any deduplication of written data. All the consumed data is being persisted to intermediate files, which are later going to be processed by Deduper, a batch job which is deduplicating data. Before data is considered as successfully persisted to a file, file needs to be successfully communicated to Completionist, a service which tracks all written intermediate files so it could detect if the hourly bucket can be closed. Only after Completionist returns 200 OK, we send ACKs back to Cloud Pub/Sub.
Many event types which are being delivered by Spotify’s Event Delivery system are too big to be completely consumed by a single instance of Consumer. This is why every event type is being handled by a dedicated cluster of machines. Every cluster of machines is backed up by a single dedicated Compute Engine managed regional instance group which is being autoscaled based on CPU usage. We’re using autoscaling to effortlessly achieve optimal usage when consuming data. In order to use autoscaling it was important to design the Consumer to be completely stateless.
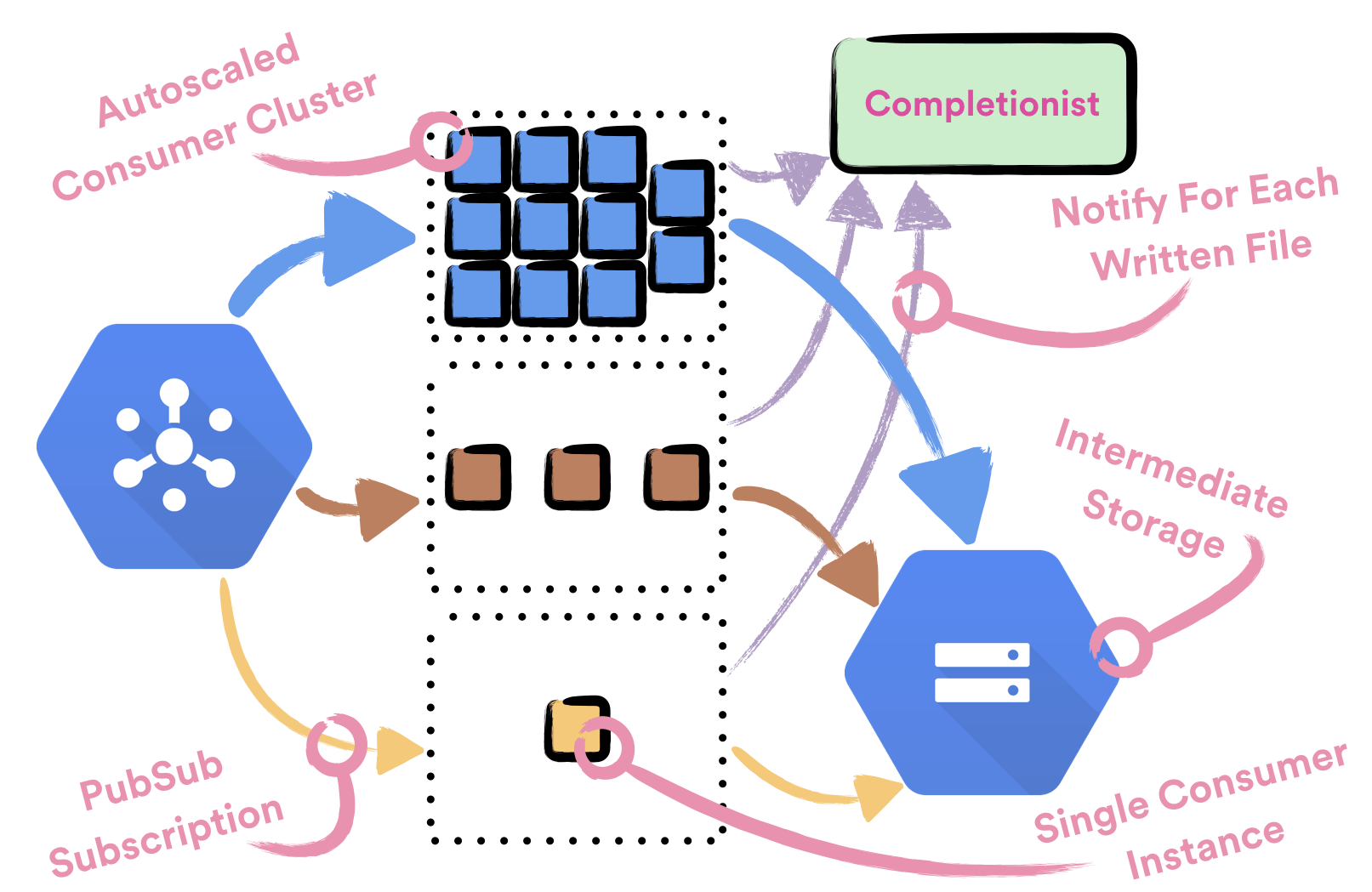
Completionist is a service which is used for detecting when it is safe to close hourly buckets. To do that Completionist keeps track of all intermediate files which are written with Consumer. Completionist exposes API which is queried by Deduper to detect if the hourly bucket was closed. If the hourly bucket was closed, it returns all the intermediate files which belong to that bucket.
Completionist uses heuristics to detect if the hourly bucket can be closed. This heuristics are based on two conditions:
- when the last intermediate file, that belongs to hourly bucket, was written and
- current value of Cloud Pub/Sub Oldest Unacknowledged Message metric.
If the intermediate file was written too recently, or Oldest Unacknowledged Message is too old, we don’t close hourly bucket.
Completionist is yet another Apollo service which is deployed with Helios. We’re using Cloud SQL to persist state of Completionist. When calculating which files belong to which hourly bucket we’re using SQL transaction to ensure consistency of produced results.
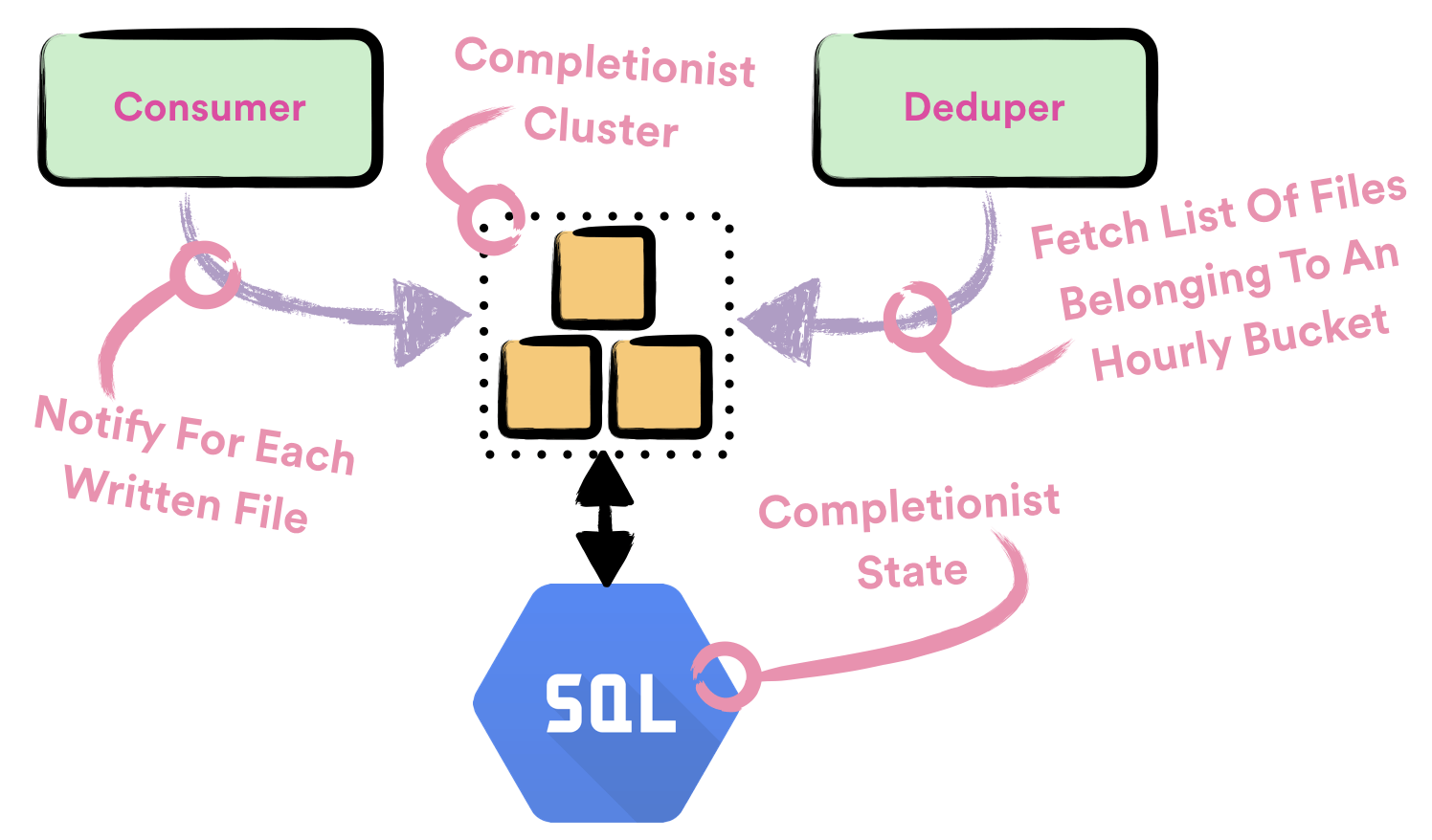
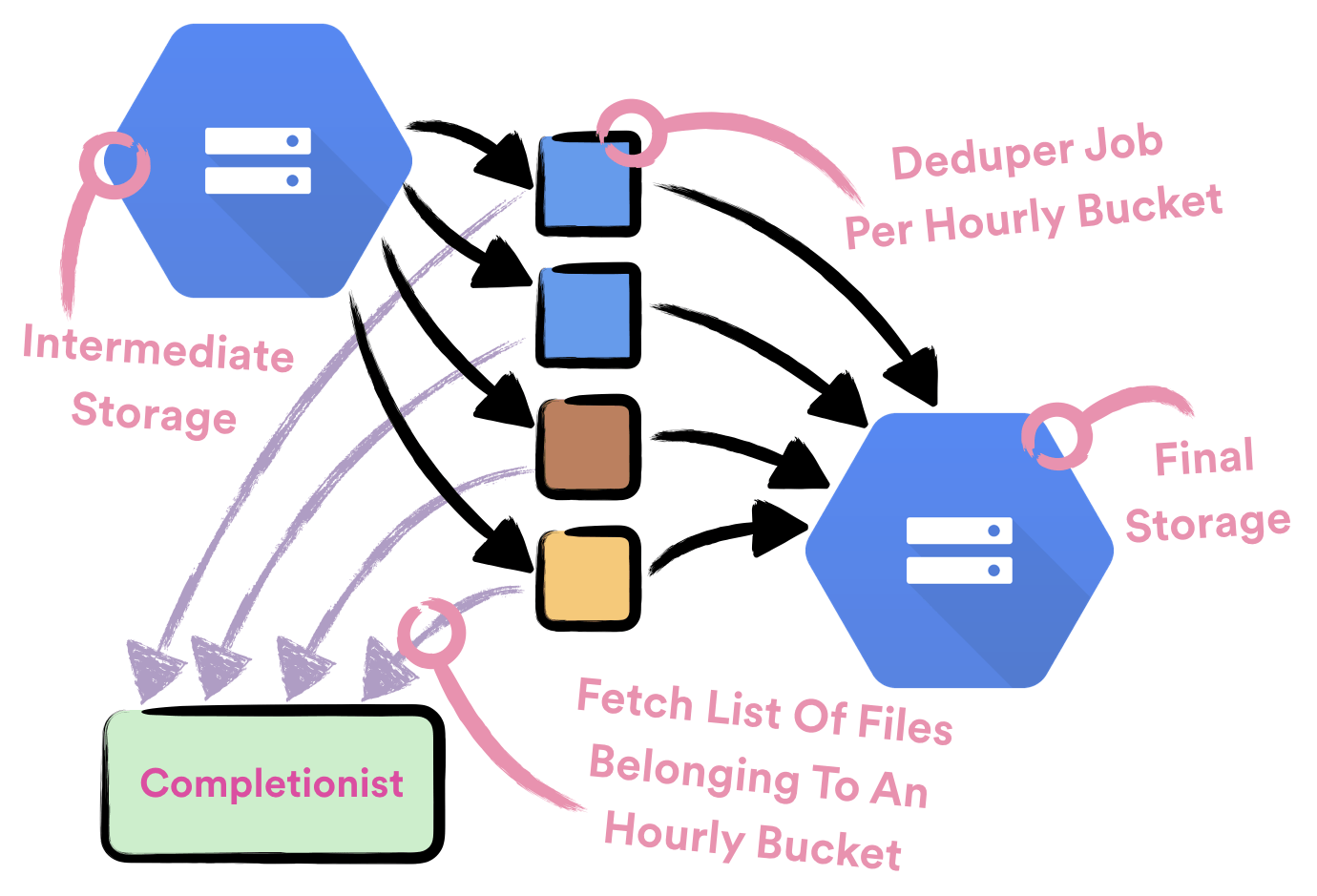
Deduper is a Crunch batch job which is used to deduplicate data in hourly buckets. It is scheduled to run once for each hourly bucket for each event type. To know which intermediate files belong to an hourly bucket and need to be processed it queries Completionist. Deduper jobs are being executed on Dataproc clusters and they’re scheduled with Styx scheduler.
After Deduper delivers deduplicated data to hourly bucket on GCS, we consider data to be successfully delivered. To export data from GCS to other storage implementations we run independent batch jobs, scheduled with Styx.
Choosing the right tool for the job isn’t the easiest of tasks. To speed up development and minimize maintenance costs we prefer using existing tools and frameworks. Sometimes none of them is meeting our requirements and we need to jump in at the deep end and do it ourselves.
Even if we’re not using Dataflow as a part of our Event Delivery system, other teams in Spotify found it to be a valuable tool in their toolbox. We have many real time pipelines being run as Dataflow stream jobs. We’re also seeing many teams rewriting their Scalding and Crunch data pipelines as Dataflow batch jobs. Since Scala is the prefered language for our data engineers, framework of choice for writing batch and streaming Dataflow jobs in Spotify is scio.
EDIT: It was brought to my attention that many operational improvements were implemented for Dataflow since the time we initially experimented with it. Notably, Dataflow jobs can now be monitored via Stackdriver monitoring, which provides querying and alerting based on metrics corresponding to job success/failure, system lag, and more.
Tags: Data




