Improving Critical Infrastructure Rollouts

Spotify began using Docker with a few prototype services in 2014. We upgraded and configured it many times since and have almost every time come across issues that were often hard to detect and fix. When the number of backend services running on Docker was low, the impact of these issues was small. As Docker adoption grew so did the risk and impact of faulty Docker changes until they reached unacceptable levels. In October 2016, we deployed a bad configuration change that significantly affected the user experience.
At this point we went back to the drawing board and realized we needed a new solution that deployed fleet-wide infrastructure changes gradually and with more control. This is a story of how operating Docker at Spotify inspired us to build a service that gave us more control over the rollout of infrastructure changes on thousands of servers.
1. Every Docker upgrade had issues
Every time we upgraded Docker, we encountered regressions or incompatibilities between Docker changes and software we run on top of it. Moreover, these issues became harder to troubleshoot and more harmful.
The two bugs we hit when upgrading Docker from 1.0.0 to 1.3.1 were straightforward to fix. Docker changed the way it set container hostnames and the way it treats CMD and ENTRYPOINT settings. Within a few days, we deployed workarounds for both regressions. This was a minor incident. Only a few teams’ build pipelines were disrupted. We weren’t so lucky on the next upgrade.
It was the summer of 2015, and we had just finished upgrading from 1.3.1 to 1.6.2. We thought the coast was clear. After a while we discovered that upgrading between these two versions of Docker can create orphaned containers – containers not managed by the Docker daemon. These containers clung to their original ports which caused our Docker orchestration tool Helios to route traffic to the wrong container. We successfully reproduced the issue by repeatedly up- and downgrading Docker. The root cause was Docker not shutting down cleanly and leaving orphaned processes behind as a result. We started monitoring orphaned container processes and submitted a patch to upstream to give Docker more time to shut down cleanly. This bug was more insidious and harder to fix than the previous two.
We finished upgrading from 1.6.2 to 1.12.1 last November. A week later on November 3 we discovered that 1.12.1 has a bug that creates orphaned docker-proxy processes. This prevented containers from running since ports weren’t being released. We quickly unblocked teams that weren’t able to deploy their services. We also helped upgrade their instances to 1.12.3. Like the previous upgrade bug, this one was subtle and difficult to fix.
2. The importance of Docker to Spotify’s backend grew and so did the risk and impact of Docker issues.
Docker adoption at Spotify began with a few prototype services in 2014. Back then only a few services were running on hundreds of docker instances. We felt confident enough to upgrade the entire testing environment, wait a week, and then upgrade all of production. We hit a couple of bugs but nothing major.
Compare this with the upgrade from 1.6.2 to 1.12.1 in October 2016. At that time, we had several thousand Docker instances running mission critical services that log in users, deliver events, and enable all clients to talk to the backend. Upgrading a Docker instance causes all containers running on that instance to restart. We have to upgrade gradually to prevent lots of services restarting all at once. Restarting critical services like access points and user login all at once creates a bad experience for users and causes reconnect storms that topple downstream services.
As of February 2017, 80% of backend services in production run as containers. As a result, Docker has gone from an experiment to being a critical piece of Spotify’s backend infrastructure. Our team is responsible for running and maintaining Docker daemons across a fleet of thousands of hosts. So we have to upgrade more gradually than ever.
3. We learned to create a gradual rollout solution for infrastructure.
We were in the midst of upgrading Docker to 1.12.1 and were 30% done. Then on Friday October 14, in trying to fix a minor race condition when provisioning new Docker instances, we rolled out a bad change. This incident revealed how our Docker deployments and fleet-wide changes in general had become too risky. We huddled and spilled ink and created a service that allowed us to rollout infrastructure changes gradually with more control.
Enter Tsunami
Tsunami enables us to create unattended, gradual rollouts of changes to configuration and infrastructure components. We can tell Tsunami to “upgrade Docker from version A to B over two weeks.” Tsunami is essentially linear interpolation as a service. Stretching deployments out over long periods improves reliability. We can detect problems while they only affect a small portion of the fleet.
Problems Tsunami solves
- The scale and responsibilities of our Docker infrastructure require gradual upgrades.
- Gradual upgrades limit the impact of bugs and give engineers time to detect and report issues.
- Our current setup makes it impossible to detect all upgrade issues by only upgrading Docker on our own services or testing instances of other services. We need to upgrade on real production services which necessitates going slowly over an evenly distributed selection of all backend services.
The primary concept in Tsunami is a “variable.” Every variable has a name and configuration controlling what values it can have and how it transitions between values over time. We made all of our Docker instances query Tsunami to ask what version of Docker they should run. Tsunami only returns a flat JSON object that indicates the desired state. It’s up to the client itself to enact the desired state.
This results in this type of roll out.
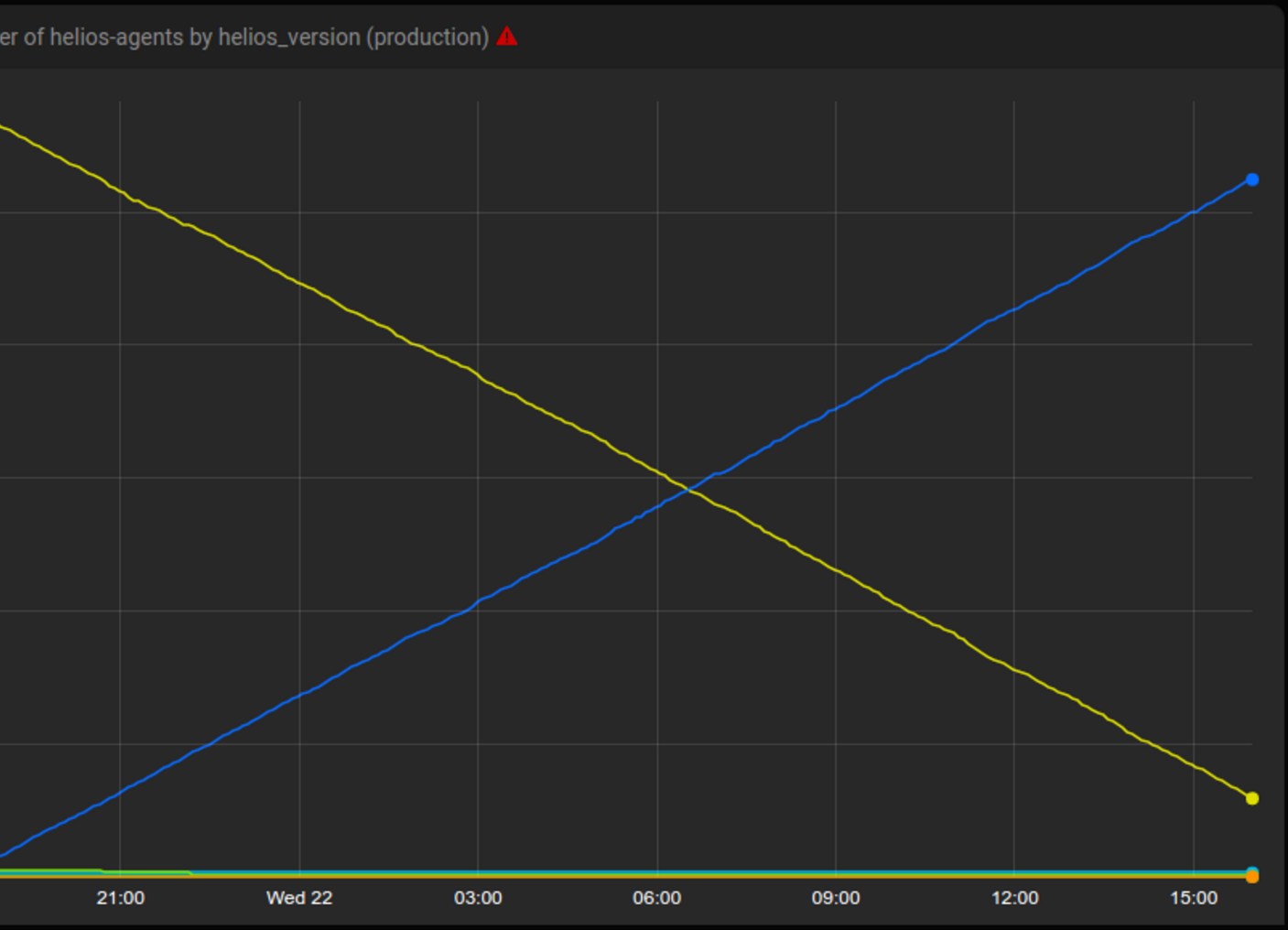
Tsunami rolling out a new version of Helios to thousands of hosts over 24 hours. Yellow is the old version and blue is the new.
Having a centralized service that controls rollouts enables us to build features that all clients would get “for free.” These include
- having an audit log that shows when a host was told to run a given version of a system service, and for what reason.
- having granular logic on what percentage of hosts in a given role are affected by an infrastructure change, with floor or ceiling (eg., 30% of the hosts in a role, but at least one host).
- monitoring of service-level objectives on machines and automatic termination of rollouts if objectives are breached.
We’re using Tsunami to upgrade Helios, Docker, and Puppet. Tsunami also helps us make configuration changes that trigger restarts of services. We hope to open-source Tsunami code in the near future. If these problems interest you, we have many opportunities to join the band.
Tags: backend




