Autoscaling Pub/Sub Consumers
Spotify’s Event Delivery system is responsible for delivering hundreds of billions of events every day. Most of the events are generated as a response to a user action, such as playing a song, following an artist or clicking on an ad. All in all, more than 300 different types of events are being collected from Spotify clients.
The Event Delivery system is one of the core pillars of Spotify’s data infrastructure since almost all data processing depends, either directly or indirectly, on data that it delivers. Any delays in delivering data can affect Spotify users’ experience since their favorite feature (like Discover Weekly) would be delayed.
It is therefore important for Spotify’s Event Delivery to be both reliable and to scale effortlessly. One easy way to achieve higher scale is to break down the problem into smaller sub-problems. In our case, instead of delivering all events through a single stream, we decided to fully isolate each event type and deliver it independently. As a result of that decision, we also achieve higher availability, since no misbehaving event can affect the delivery of other events.
As the backbone of our system we use Cloud Pub/Sub. Having full isolation between different event types means that each event stream is published to its own dedicated topic that is consumed and exported to Cloud Storage by a dedicated ETL process.
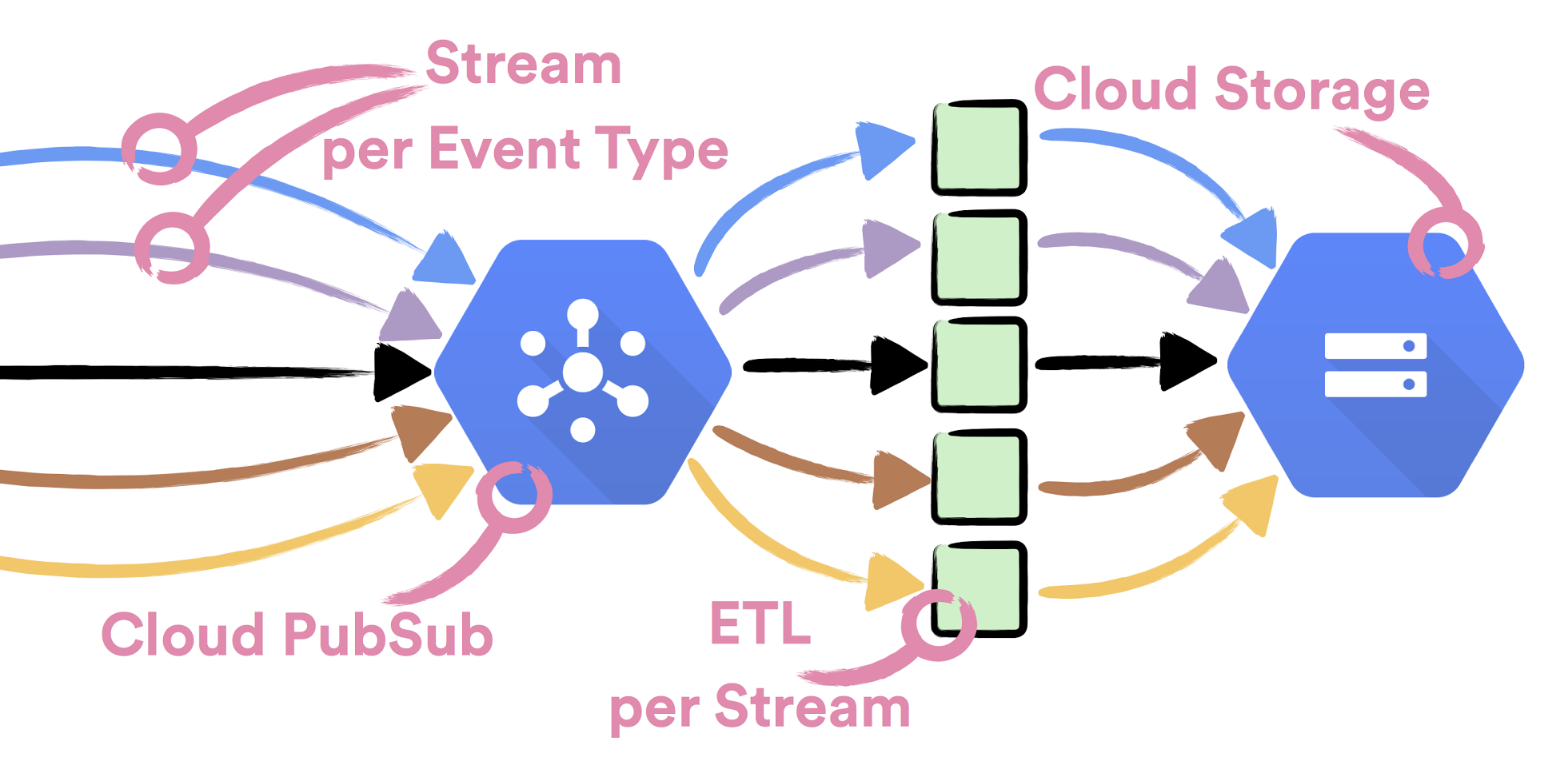
The first step of the ETL process, which is built as a set of microservices and batch jobs, is to consume data from a Cloud Pub/Sub subscription and export it to an intermediate bucket on Cloud Storage. For that task, we’ve built a special micro service – Pub/Sub Consumer.
Pub/Sub Consumer
To speed up development, we decided to build Consumer as any other microservice in Spotify. We wrote it as an Apollo service, packaged it as a Docker image with a Maven plugin and deployed it with Helios to machines which are managed by Puppet. An important factor in why we made this decision was that both our monitoring and service discovery depend on Puppet-managed daemons.

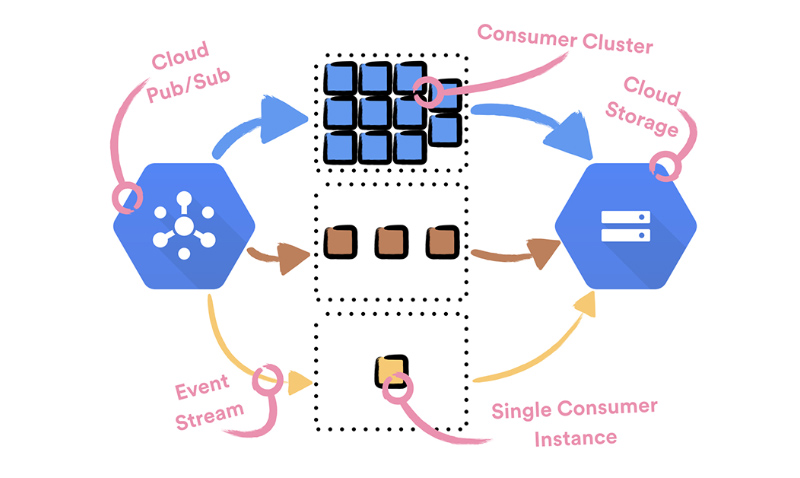
The volume of event streams flowing through the Event Delivery system varies a lot. Some streams only rarely receive events (less than 1 event per hour), while other streams have extremely high volume (more than 300k events per second). To both reliably handle high volume event streams and not waste resources for low volume event streams, each event stream is handled by a separate cluster—set of one or more instances—of Consumers.
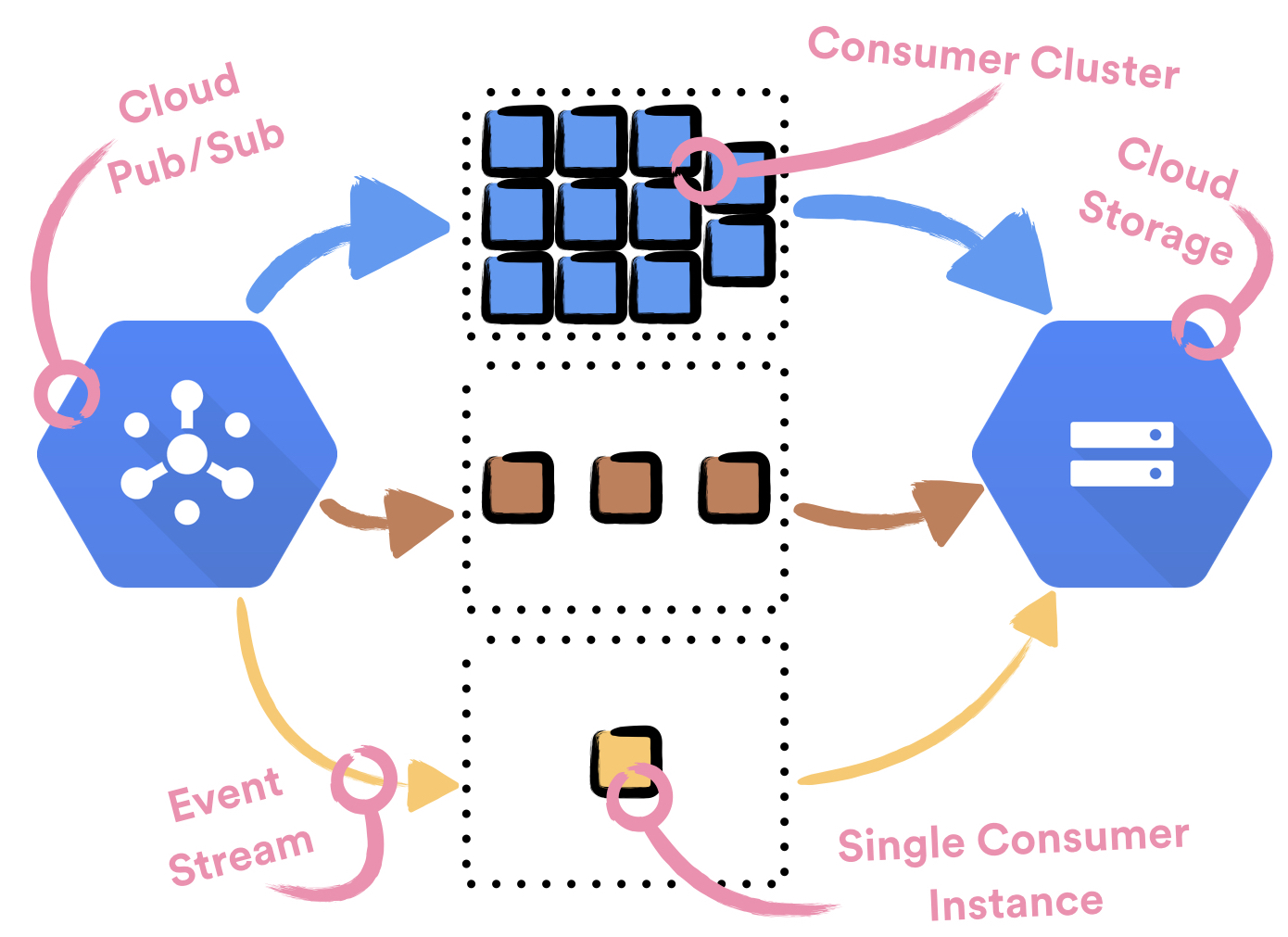
Each Consumer instance is deployed to and runs on a dedicated machine. This is due to the limitations of the service stack—Puppet, Service Discovery and Helios—we use to currently manage services in Spotify. Each consumer cluster is backed up by a single Compute Engine managed regional instance group.
To achieve optimal usage, we need to handle event streams with optimally sized clusters. Since there are too many events for cluster sizes to be managed by hand, we decided to enable CPU based autoscaling on each of the clusters. We could do that since Consumer is a stateless service and its CPU metric correlates well with its usage.
As long as nothing unexpected happens, autoscaling works well. When problems occur, if not handled properly, things can get really ugly.
Autoscaling – The Ugly Parts
Handling Unhealthy Machines
Whenever autoscaler decides to spin up a new Consumer machine, a chain of provisioning steps is triggered:
- A new machine gets provisioned
- It gets registered in Spotify’s DNS
- Puppet runs on a machine and installs necessary packages (including Docker, Helios agent and monitoring daemon)
- Helios agent registers with Helios master
- Helios master instructs Helios agent to deploy Consumer instance
- Consumer instance starts running on Docker
If any of the aforementioned steps fail, a machine will end up in an unusable state. Surprisingly, the most common reason for provisioning to fail is Docker. It very often ends up in a zombie state where the only possible remediation is to restart the machine. After an investigation, we could link the issues we were experiencing to this bug.
Autoscaler uses average CPU usage to decide how many machines should be part of the cluster. An unfortunate consequence of using the average is that a single zombie machine can push the full cluster—especially if it consists of fewer than 3 machines—into a broken state. This is a natural consequence of the way average is calculated; the average of one zombie machine, which has ~0% CPU usage, and one overloaded machine, which has ~100% CPU usage, is 50%. In such a case, if our target CPU usage were higher than 50%, autoscaler would not decide to add more machines.

Considering that Docker issues were affecting significant amounts of machines in our fleet, we needed to find a solution. Our first try to solve the problem was to use the default HTTP healthchecker. Instead of solving the problem, this just replaced Docker issues with Puppet issues: a “feature” of the default healthchecker is that unhealthy machines are replaced with the new machines which have exactly the same name. This in turn prevented machines from re-registering with Puppet master and applying the Puppet manifest. The second try, which worked, was to write our own HTTP healthchecker that destroys unresponsive machines using Compute Engine API directly. Once machines are destroyed, autoscaler replaces them with new machines.
Fine Tuning Machine’s CPU usage
Google’s autoscaler is configured using a single threshold parameter (aka target usage). This makes autoscaler tricky to configure. This is amplified by autoscaler being sensitive to short CPU spikes (shorter than 1 min), which cause it to immediately provision more machines. A lot of trial-and-error is needed until the perfect balance can be found.
Equilibrium can be easily broken by adding new daemon(s) to machine. Our unfortunate way of noticing that the autoscaler was pushed out of balance was getting alerted because all of our resources were consumed. To avoid such a scenario, we need to keep the daemons’ CPU usage under control. We found cpulimit to be a perfect tool for that job.
Issues with downstream services, upon which Consumer depends on to export data, are another common reason when autoscaler goes bonkers. This is the case since the rate at which events are being queued for processing is independent of how fast Consumer exports them: if Consumer isn’t exporting events at the rate they’re being published, a backlog of events pending to be processed forms on a subscription. When Consumer isn’t able to export events it still spends some CPU cycles processing them without removing the consumed events from a Pub/Sub subscription. A growing backlog of queued up events causes Consumer to spend more CPU cycles processing events without exporting them, which causes autoscaler to add more machines, which causes more CPU cycles to be spent on processing events without exporting them, which causes backlog to grow more, which causes autoscaler to add more machines, which causes more CPU cycles to be spent, and so on…

We learned, the hard way, that exponential backoffs are a must in order to handle such scenarios. Every time a Consumer is not able to export events to Cloud Storage, it sleeps for some amount of time before trying again. Sleep time is calculated as an exponential function of the number of failed requests within a sliding window. Sleeping is a crude, but effective way of suppressing the CPU usage, which tricks autoscaler into not provisioning more machines until the external service is back to normal.
Next steps
Resource usage of this system is one of the areas where we would like to improve. We’re looking closely at how can we use Kubernetes to run the system. If that were the case, the biggest resource optimisation would come from the fact that Kubernetes does bin packing. This would enable us to run several instances of Consumer on a single machine, which would decrease overhead of supporting services that we have today. Today, each Consumer machine has 4 CPUs, out of which 2 CPUs are used for running the actual Consumer instance, while the other 2 CPUs are used by Puppet, the monitoring daemon, the Cloud Logging daemon…
If we went the Kubernetes route and used Kubernetes Engine, we wouldn’t be able to depend on Puppet any more. Unfortunately this leaves us in uncharted waters (in the Spotify universe) on how to do monitoring of our services without a Puppet-managed monitoring daemon.
If this sound like the type of problem you would like to help us with, come and join us. We have fika!
Tags: Data




