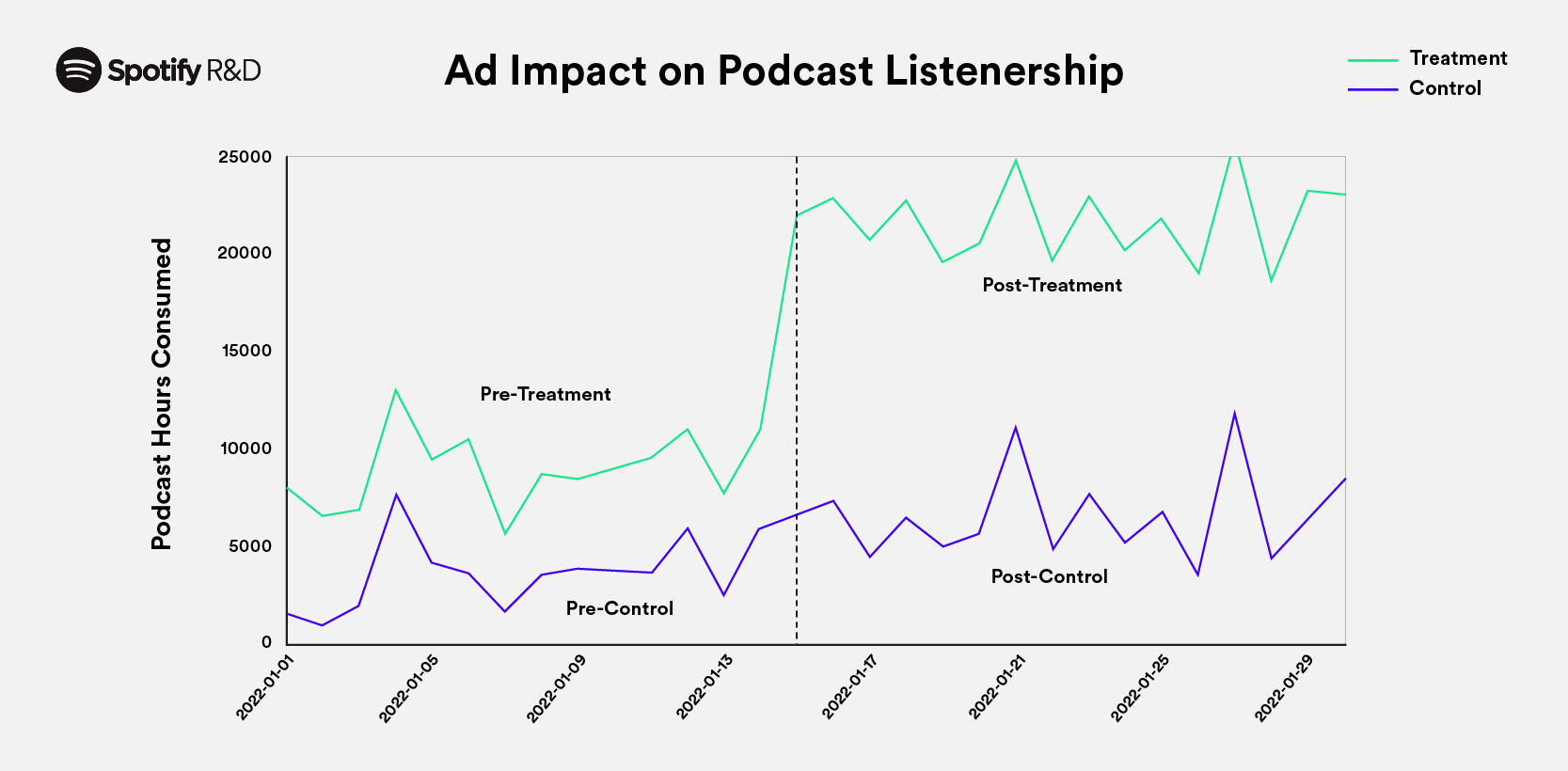
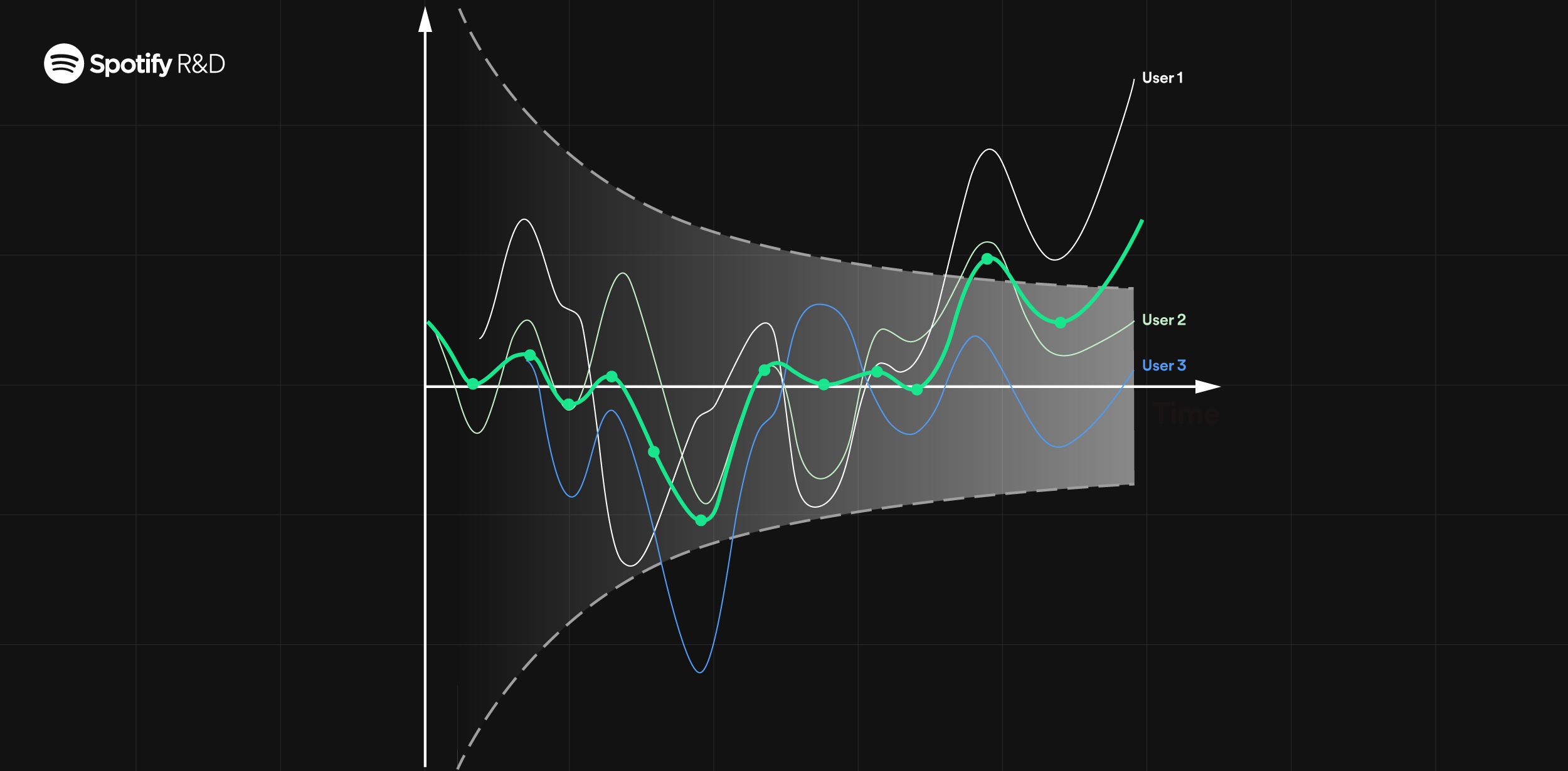
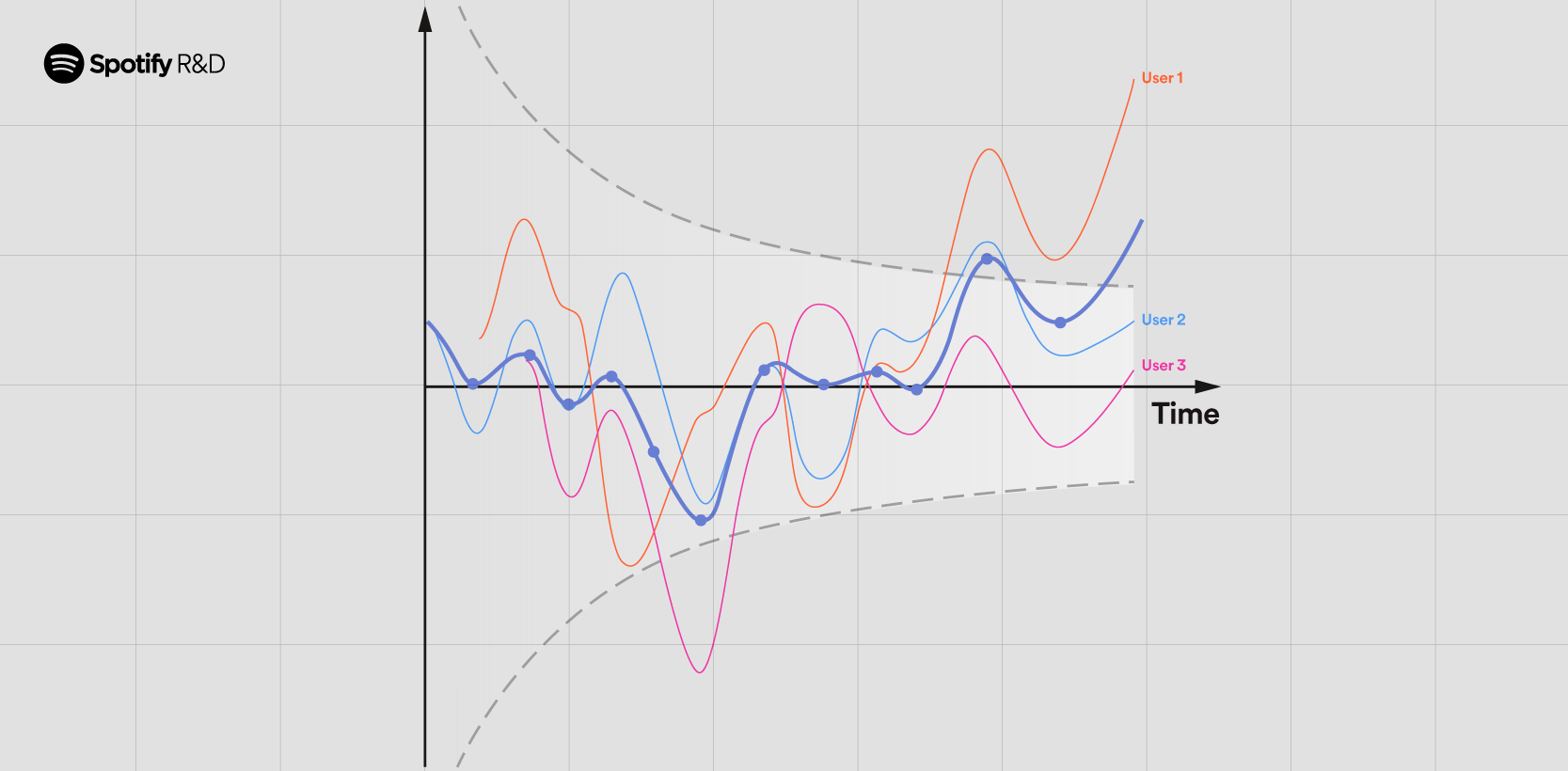
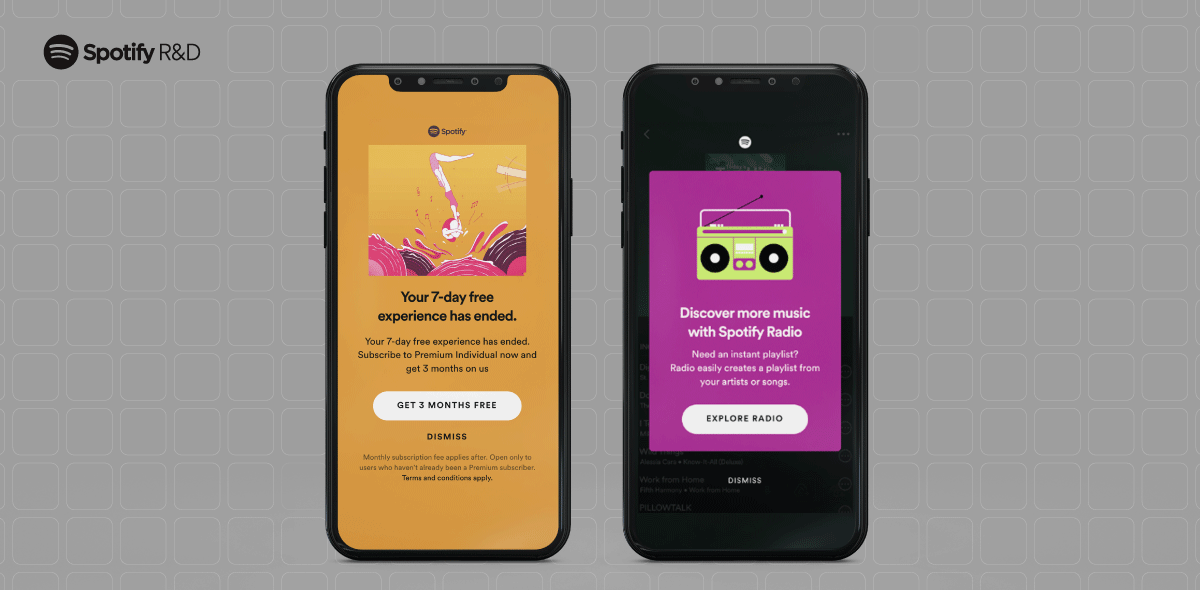
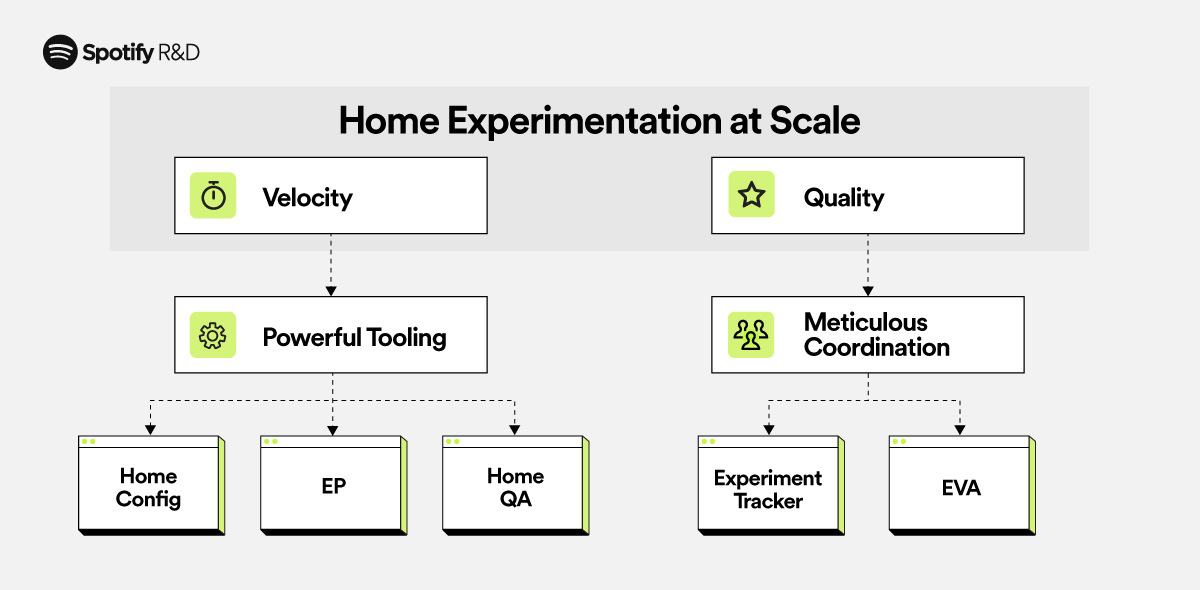
April 30, 2024
Read about the magic behind the music & more.
Welcome to our official technology blog.
Today, we announced Spotify’s latest products and services for companies adopting Backstage, the open source framework for building IDPs.



](https://storage.googleapis.com/production-eng/1/2024/01/EN212-FOSS-Fund-2023-QA_QA-1200x590_v2.png)
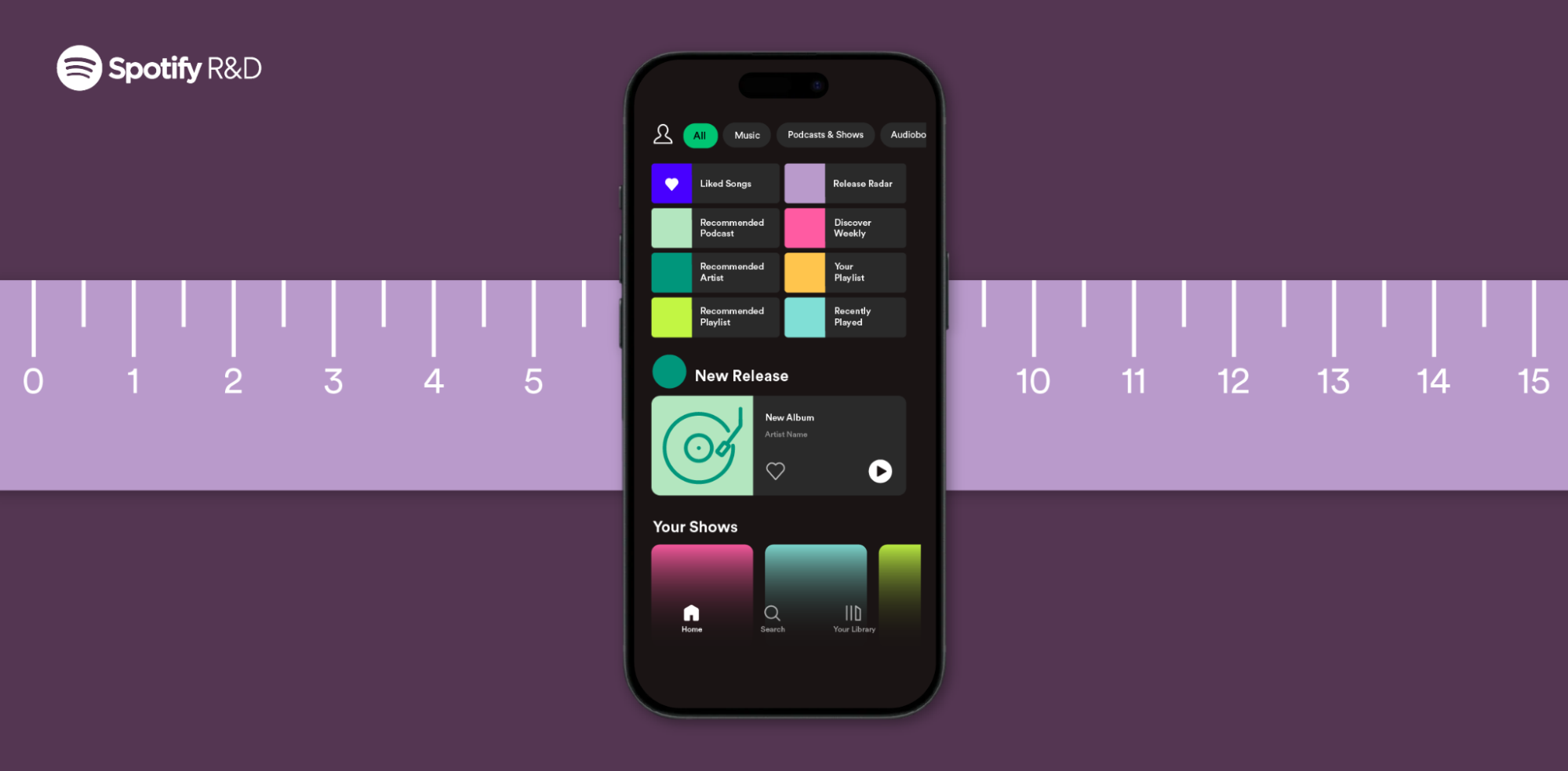

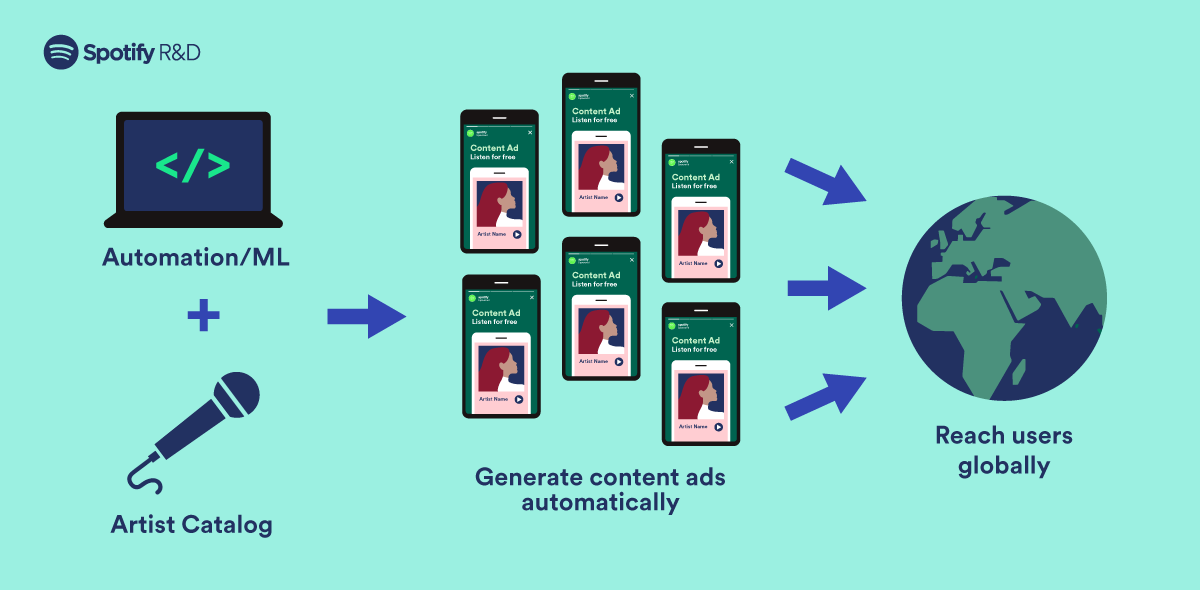

](https://storage.googleapis.com/production-eng/1/2023/10/EN201_FOSSFund23Winners_blog-post_Op-2symmetrical-1200x-590.png)
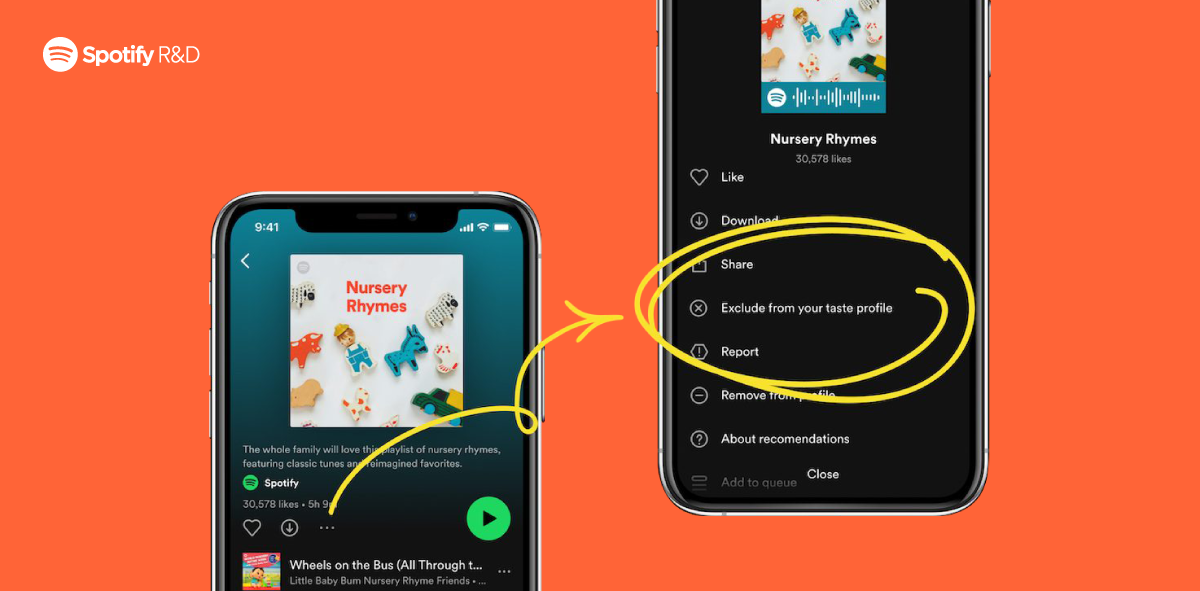
](https://storage.googleapis.com/production-eng/1/2023/10/EN205_Kelsey_ngn_1200x590.png)