September 21, 2015
Cassandra: Data-Driven Configuration
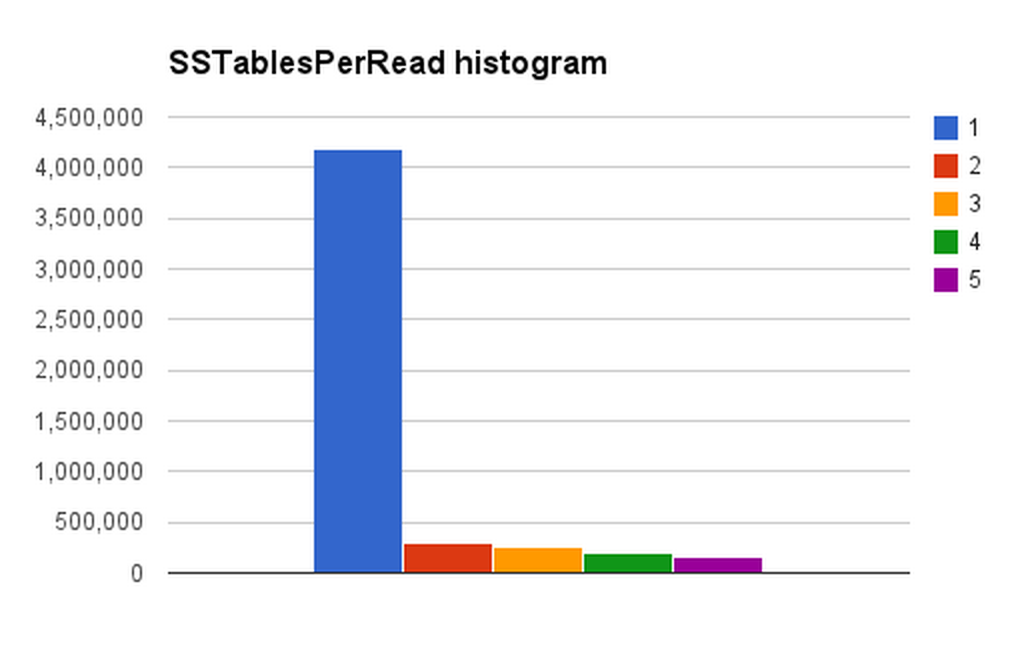
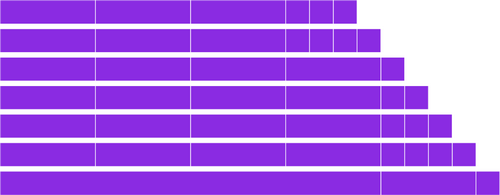
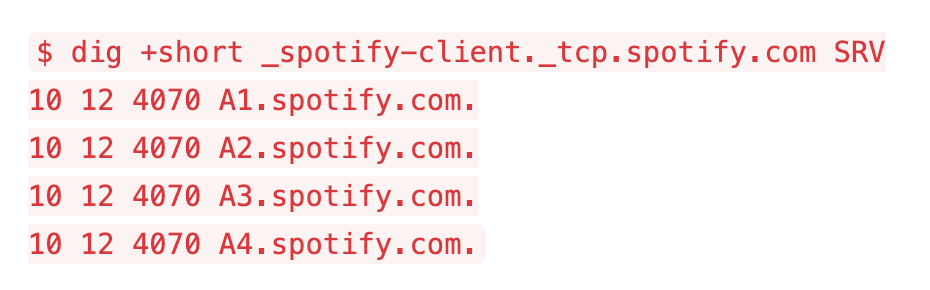
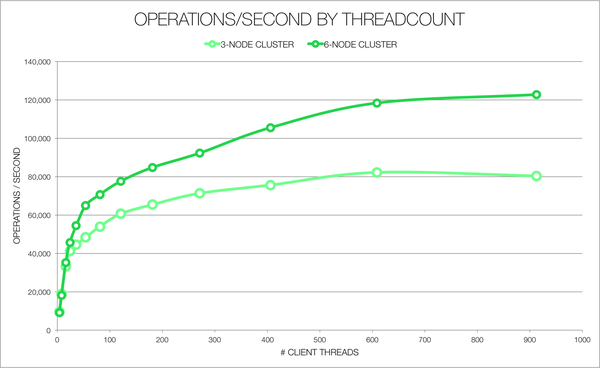
Spotify currently runs over 100 production-level Cassandra clusters. We use Cassandra across user-facing features, in our internal monitoring and analytics [...]