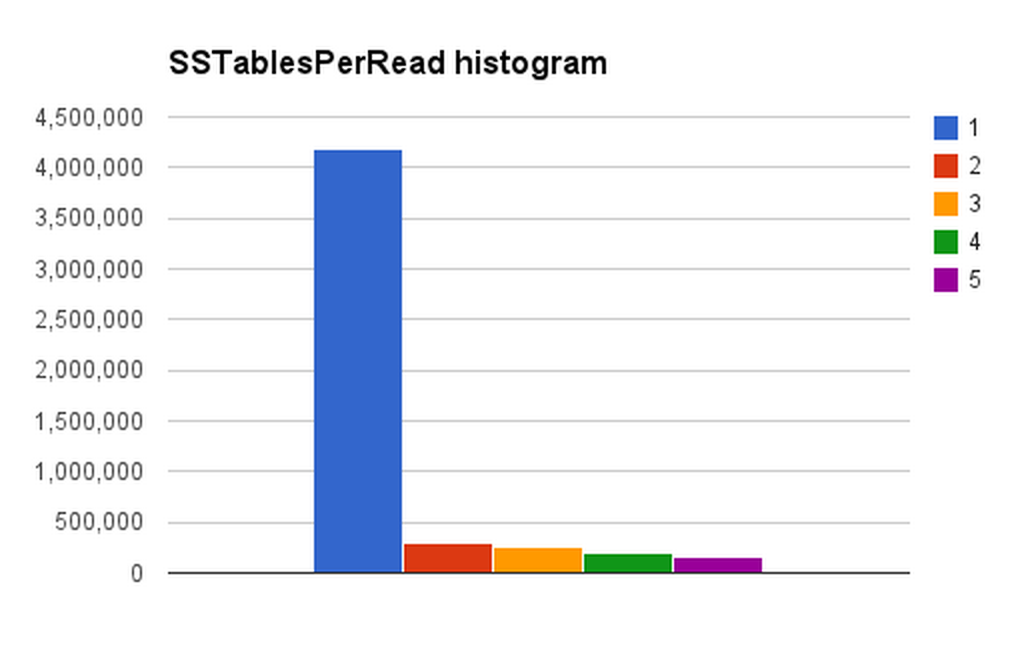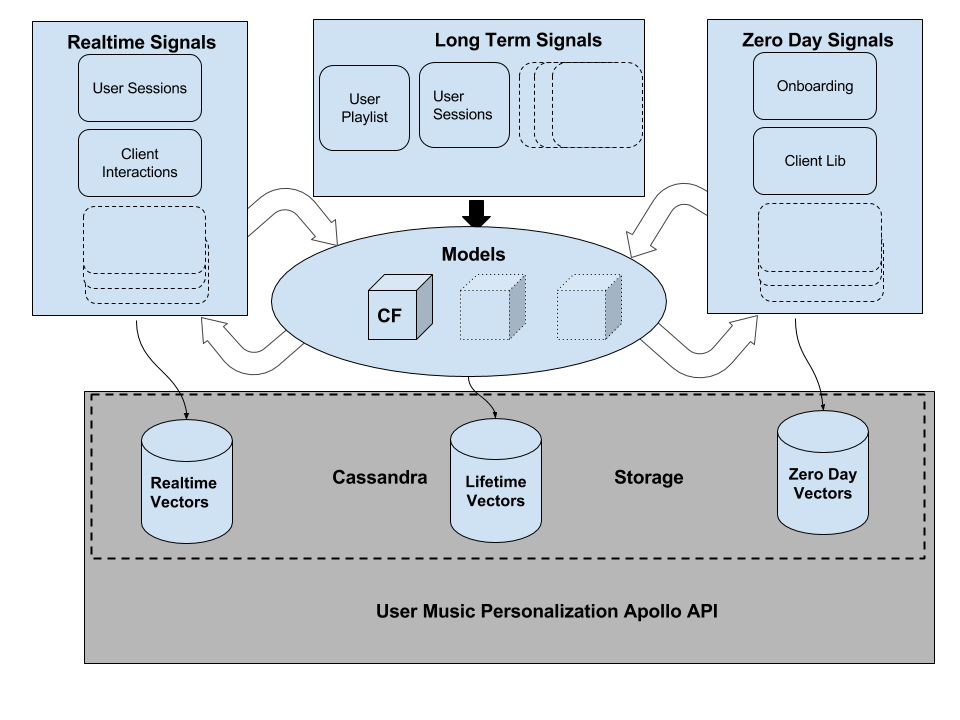
August 7, 2016
Commoditizing Music Machine Learning : Services
Five years ago, music personalization at Spotify was a tiny team. The team read papers, developed models, wrote data pipelines [...]