Managing Machines at Spotify
Introduction
When you log into Spotify, browse through your Discover Weekly playlist, and play a track, you’re interacting with some of our fleet of around 12,000 servers.
Spotify has historically opted to run our core infrastructure on our own private fleet of physical servers (aka machines) rather than leveraging a public cloud such as Amazon Web Services (AWS). Our fleet consists of a minimal set of hardware configurations and is housed in four datacenters around the world. While we heavily utilise Helios for container-based continuous integration and deployment (CI/CD) each machine typically has a single role – i.e. most machines run a single instance of a microservice.
At Spotify we believe in every team having ‘operational responsibility’. The people who build a microservice deploy the microservice, and manage the machines it’s deployed to. As you might imagine allowing hundreds of engineers to reliably manage thousands of machines is a complicated proposition.
In this post we will recount the history of Spotify’s machine management infrastructure. We’ll provide some detail on the technical implementations, and how those implementations affected the productivity and happiness of our engineers.
2012 and Earlier – Prehistory
When Spotify was a smaller company it was feasible to have a traditional, centralised operations team. The team was constantly busy fighting fires and handling every operations task under the sun. Nonetheless this was a clever operations team – a team who didn’t want to manage a rapidly growing fleet of machines by hand.
One of the first tools built to manage machines at Spotify was the venerable ServerDb. ServerDb tracks details like a machine’s hardware specification, its location, hostname, network interfaces, and a unique hardware name. Each machine also has a ‘ServerDb state’, for example ‘in use’, ‘broken’, or ‘installing’. It was originally a simple SQL database and a set of scripts. Machines were installed using the Fully Automated Installer (FAI) and often managed using moob, which provides serial console access and power controls. Our heavily used DNS zone data was hand curated and required a manual push to take effect. All machines were (and still are) managed by Puppet once their base operating system (OS) was installed.
Various parts of the stack were replaced over the years. FAI was replaced with Cobbler and debian-installer. Later, debian-installer was replaced with our own Duck. While many steps of the provisioning process were automated, these steps could be error prone and required human supervision. This could make provisioning 20 new machines an unpredictable and time-consuming task. Engineers requested new capacity by creating an issue in a JIRA project, and it could take weeks or even months for requests to be fulfilled.
Late 2013 – The IO Tribe
Spotify has always liked Agile teams (or squads, in Spotify parlance). In late 2013 the operations team became part of the newly formed Infrastructure and Operations (IO) organisation. New squads were formed around specific problem spaces within operations. Our squad took ownership of provisioning and managing Spotify’s machines.
From the beginning we envisioned a completely self service machine management service, but the squad was swamped with busy work. We were inundated with requests for new machines, and constantly playing catchup on machine ingestion – the process of recording newly racked machines in ServerDb. We decided to start small and cobble together some minimal viable products (MVPs) to automate the major pain points in order to claim back time to work on bigger things. We began the effort on three fronts.
DNS Pushes
DNS pushes were one of our earliest wins. Initially the operations team had to hand-edit zone files, commit them to revision control, then run a script on our DNS master to compile and deploy the new zone data. We incrementally automated this process over time. First we built a tool to automatically generate most of our zone data from ServerDb. We then added integration tests and peer review that gave us high confidence in the quality of our changes. Soon thereafter we bit the bullet and automated the push. Cron jobs were created to automatically trigger the above process. Finally we tied up the loose ends, such as automatic creation of zones for new ServerDb subdomains.
Machine Ingestion
By the time our squad took ownership ServerDb had become a RESTful web service backed by PostgreSQL. It recorded hundreds of machines by parsing CSV files hand-collated by our datacenter team. These files contained data such as rack locations and MAC addresses that were easy for a technician to misread. We also assigned each server a static unique identifier in the form of a woman’s name – a shrinking namespace with thousands of servers.
Our goal was to completely automate ingestion such that no human intervention was required after a machine was racked. We started by switching our network boot infrastructure from Cobbler to iPXE, which can make boot decisions based on a machine’s ServerDb state. ‘In use’ machines boot into their production OS. Machines in state ‘installing’ and machines unknown to ServerDb network boot into a tiny Duck-generated Linux environment we call the pxeimage, where they run a series of scripts to install or ingest them, respectively.
In order to perform ingestions without human interaction we abandoned our woman’s name based machine naming scheme in favour of using the machines’ unique and programmatically discoverable serial numbers. Unknown machines run a reconnaissance script that determines their serial number, hardware type, network interfaces, etc and automatically registers them with ServerDb.
Provisioning Requests
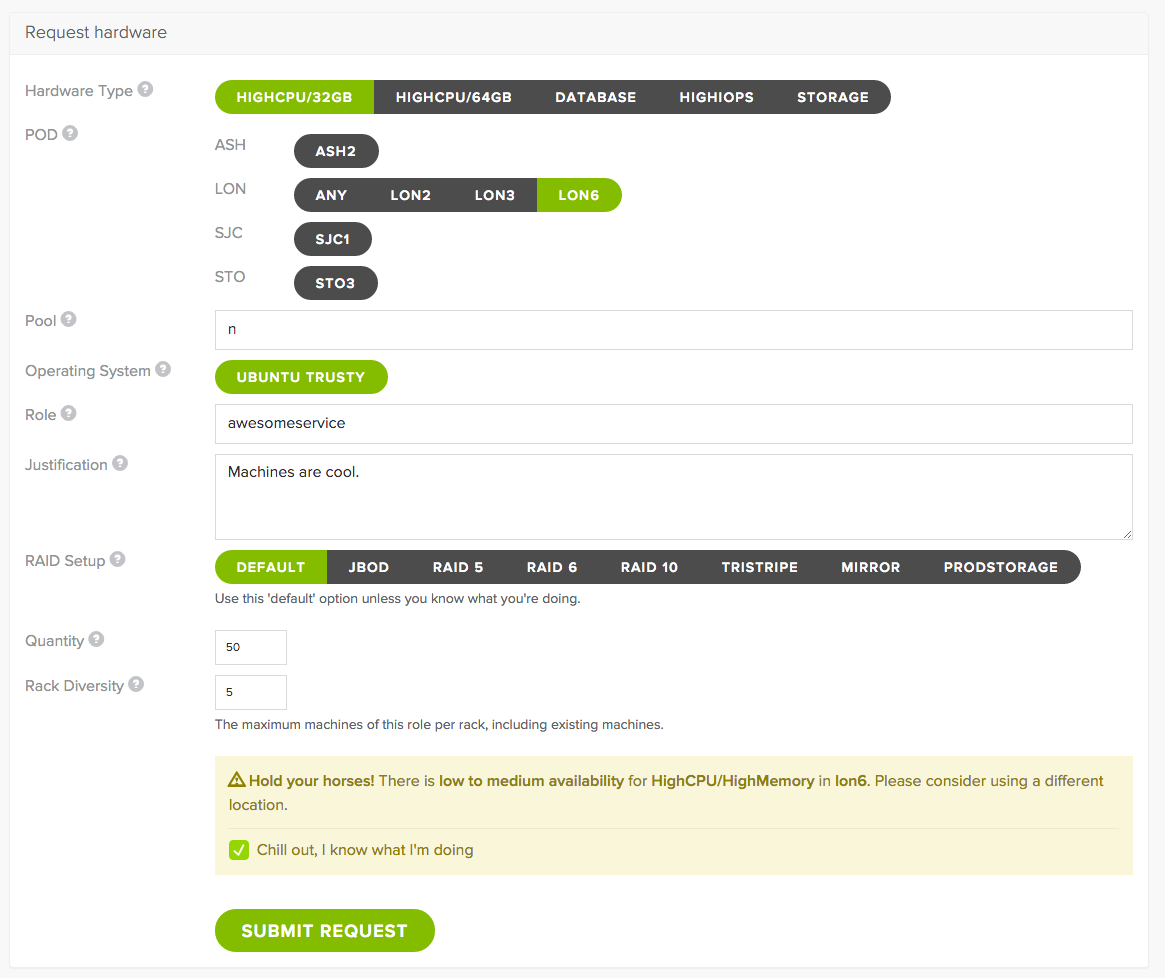
At some point in prehistory a kind soul had written ‘provgun’ – the Provisioning Gun. Provgun was a script that read a JIRA ‘provisioning request’ issue and shelled out to the commands necessary to fulfill that request. A provisioning request specifies a location, role, hardware specification, and number of machines. For example “install 10 High IO machines in London with the fancydb role”. Provgun would find available machines in ServerDb, allocate them hostnames, and request they be installed via ServerDb.
ServerDb used Celery tasks to shell out to ipmitool, instructing target machines to network boot into the pxeimage. After installing and rebooting into the new OS Puppet would apply further configuration based on the machine’s role.
One of the first questions we asked was “can we put provgun in a cron loop?” like our DNS pushes. Unfortunately provgun was very optimistic, and did not know whether the commands it run had actually worked. We feared that naively looping over all open provisioning requests and firing off installs would increase rather than reduce busy work.
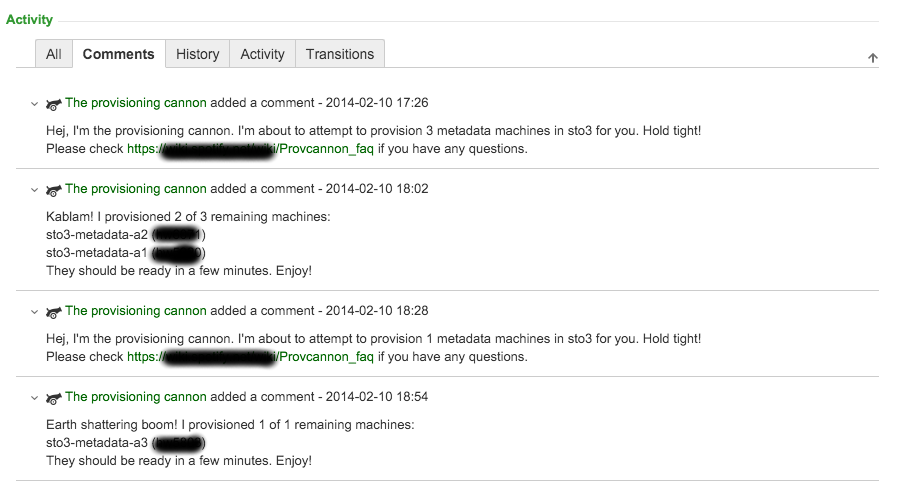
Our solution was provcannon – the Provisioning Cannon. provcannon was a Python reimplementation of provgun that monitored each installation to ensure success. This monitoring allowed us to retry failed installs with exponential backoff, and to select replacements for consistently uninstallable machines. We configured provcannon to iterate over all outstanding provisioning requests twice daily.
Impact
By focusing our efforts on automating DNS changes, machine ingestion, and provisioning requests we reduced the turnaround time for getting capacity to Spotify engineers from weeks to hours. DNS updates went from something that made most of us very nervous to a process we hardly thought about anymore. Equally important was that our squad was freed from boring and error prone work to focus on further improving the turnaround time and experience for our fellow engineers.
Mid 2014 – Breathing Room
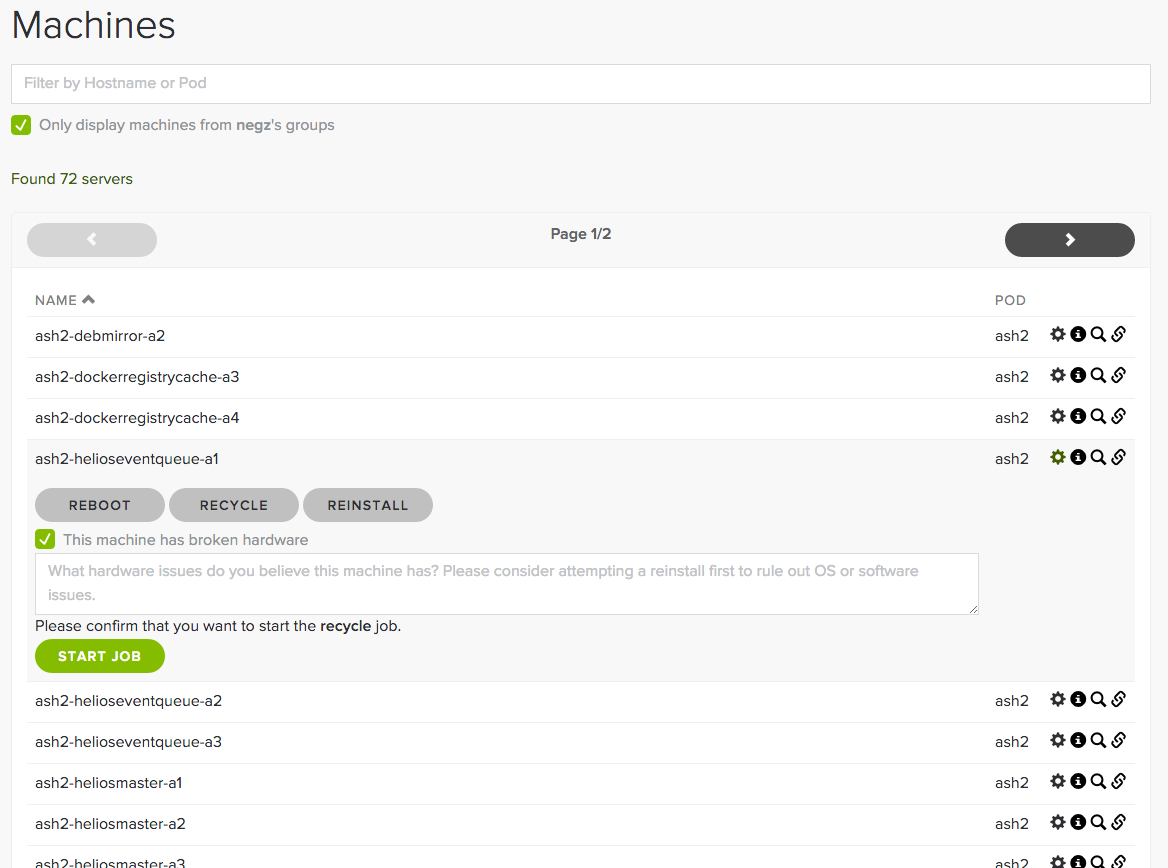
A few months after deploying our initial stopgaps things were calmer in the squad. Longtime Spotify engineers were pleased with the faster turnaround times for new machines, but newcomers used to AWS and similar platforms were less happy waiting a few hours. Parts of our infrastructure were unreliable, and we’d only automated installations. Power-cycling malfunctioning machines and ‘recycling’ superfluous ones back to the available pool still required us to read a JIRA issue and run a script. We decided it was time to execute on our grand goal – a self service web portal and API for Spotify engineers to manage machines on demand.
Neep
Starting at the bottom of the stack we first built a service – Neep – to broker jobs like installing, recycling, and power cycling machines. Neep runs in each datacenter on special machines patched into the out of band management network. Due to operational pains with Celery we built Neep as a light REST API around RQ – a simple Redis based job queue. We chose Pyramid as our blessed web framework for pragmatic reasons; we’d inherited ServerDb as a Pyramid service and wanted a minimal set of technologies.
{
"status": "finished",
"result": null,
"params": {
},
"target": "hardwarename=C0MPUT3",
"requester": "negz",
"action": "install",
"ended_at": "2015-07-31 17:45:53",
"created_at": "2015-07-31 17:36:31",
"id": "13fd7feb-69d7-4a25-821d-9520518a31d6",
"user": "negz"
}
An example Neep job.
Much of provcannon’s logic was reusable in Neep jobs that manage installation and recycling of machines. These jobs are effectively the same from Neep’s perspective. Neep simply sets the machine’s ServerDb state to ‘installing’ or ‘recycling’ to request the pxeimage either install a new OS or sanitize an old one and triggers a network boot. In order to remove the complication of shelling out we replaced calls to ipmitool with OpenStack’s pyghmi IPMI library.
Sid
Initially we put Neep through its paces by adapting provcannon to trigger Neep jobs. Once we’d worked out a few bugs in our new stack it was time to tie it all together, and Sid was born.
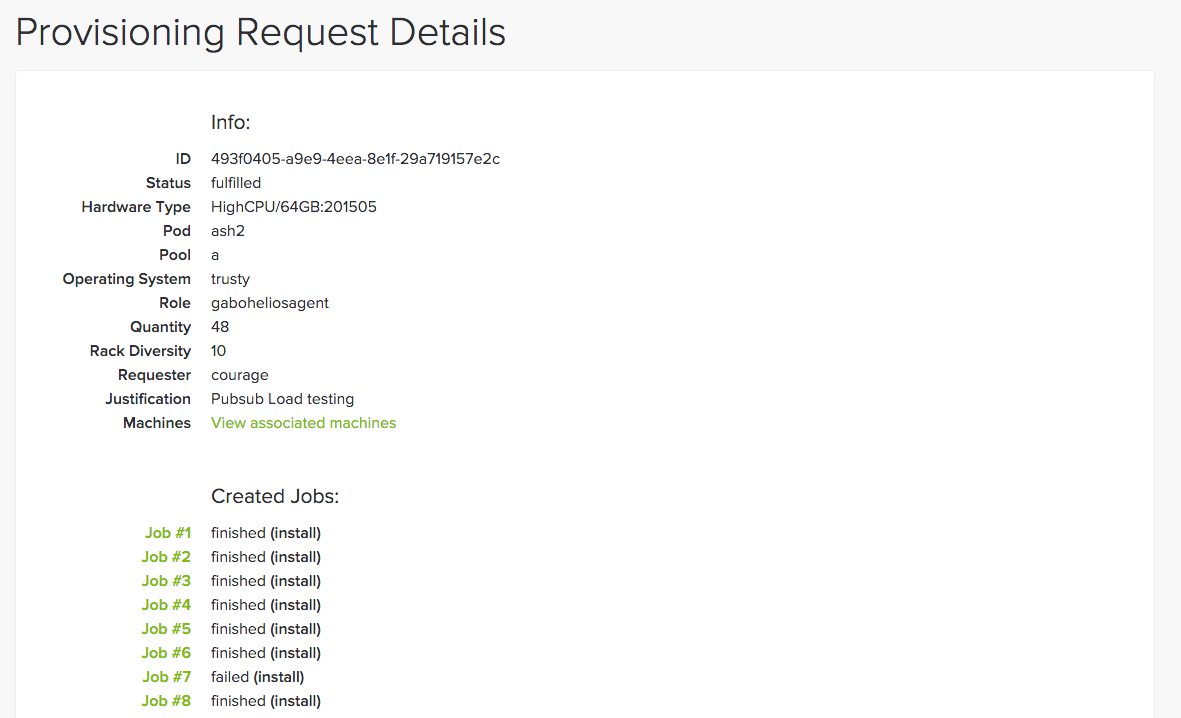
Sid is the primary interface for engineers to request and manage machines at Spotify today. It’s another Pyramid REST service that ties together machine inventory data from ServerDb, role ownership data from Spotify’s internal microservice database, and machine management jobs in Neep to allow squads at Spotify to manage their services’ capacity. It expands on the parts of provcannon’s logic that find and allocate the most appropriate machines to fulfill a provisioning request. Sid’s charming Lingon UI was a breeze to build on top of its API, and has supplanted JIRA as the provisioning request interface.
Impact
Sid and Neep have not been the only improvements in the modern machine management stack at Spotify. DNS zone data generation has been rebuilt. We apply regularly auto-generated OS snapshots at install time rather than performing time consuming Puppet runs. The culmination of these improvements is that requests to provision or recycle capacity are fulfilled in minutes, not hours. Other squads have built tooling around Sid’s API to automatically manage their machine fleet. As the face of the provisioning stack at Spotify Sid is one of the most praised services in IO. Sid has fulfilled 3,500 provisioning requests to date. It has issued 28,000 Neep jobs to install, recycle, or power cycle machines with a 94% success rate. Not bad considering the inherent unreliability of individual machines in a datacenter.
Mid 2015 – The State of the Art
In 2015 Spotify decided to start migrating away from our own physical machines in favour of Google’s Cloud Platform (GCP). This paradigm shift challenged us to envision a way for many teams of engineers to manage a lot of cloud compute capacity without stepping on each others’ toes.
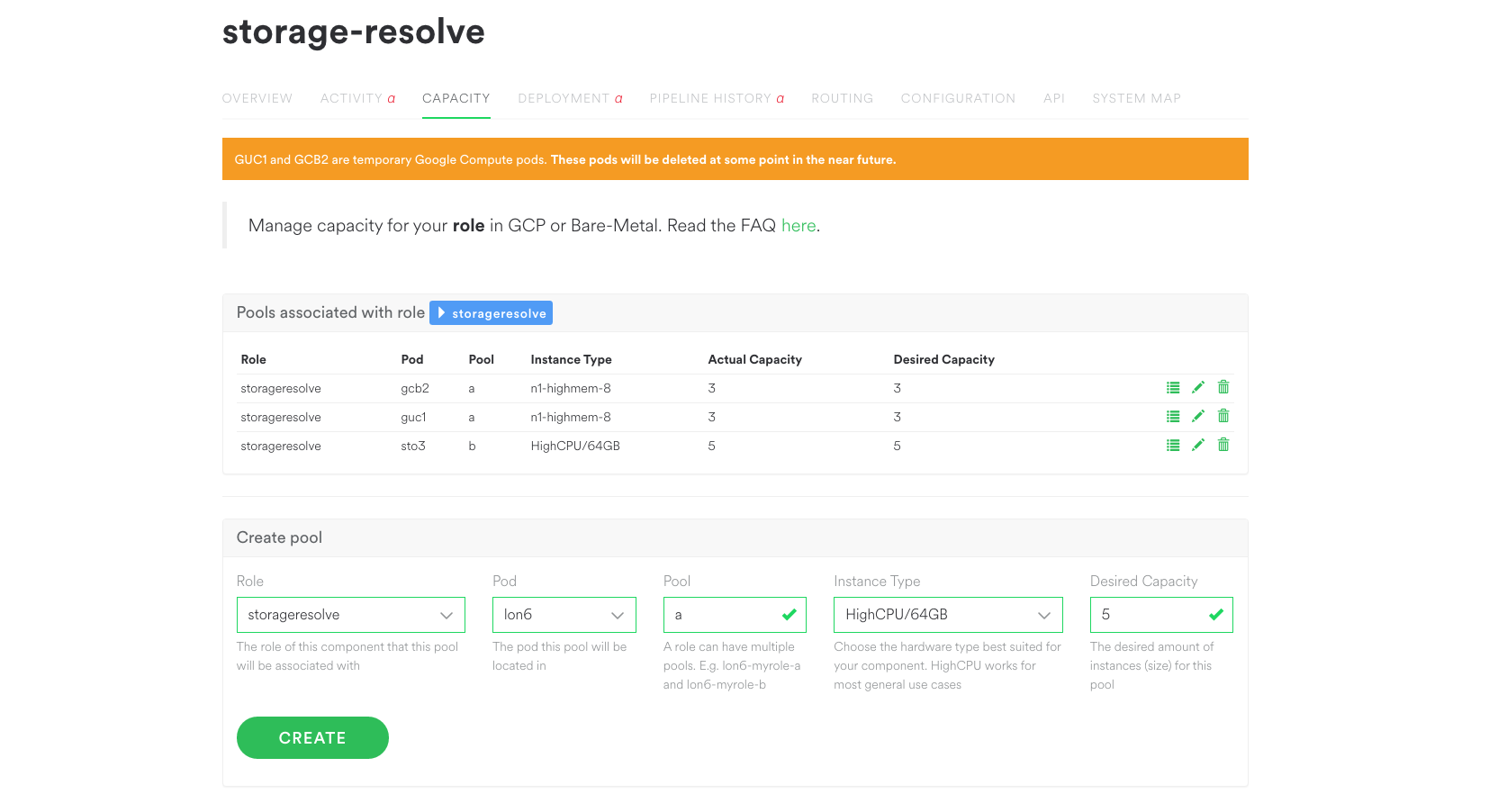
Spotify Pool Manager
In an effort to avoid the ‘not invented here’ trap our squad assessed Google’s capacity management offerings. We wanted a tool that could enforce Spotify’s opinions and patterns in order to provide engineers with an easy and obvious path to get compute capacity. We felt the Developer Console was powerful, but too flexible. It would be difficult to guide engineers towards our preferred settings. Deployment Manager was also powerful, and could enforce our opinions, but in a trial our engineers found it difficult to use.
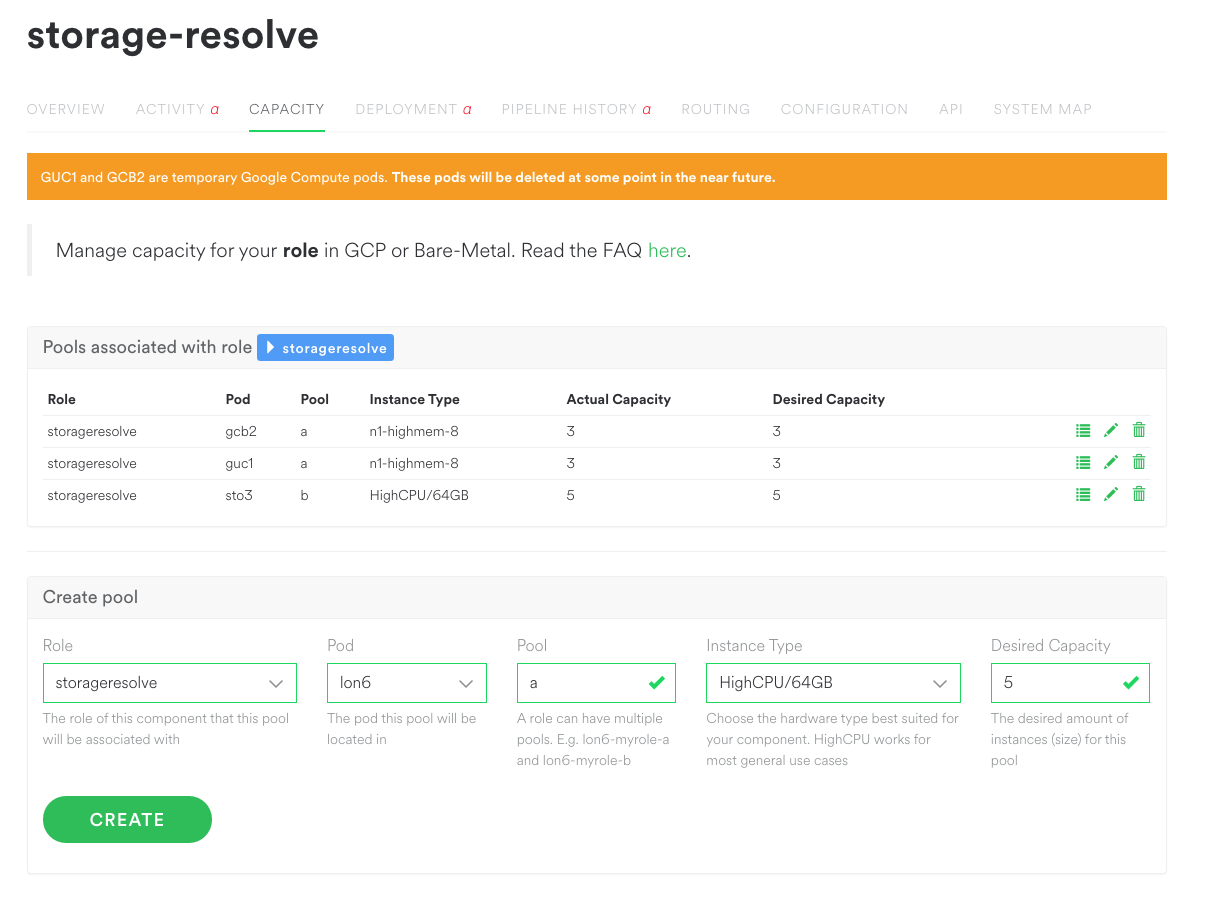
After providing feedback to Google we began building Spotify Pool Manager. SPM is a relatively light layer that frames Google’s powerful Compute Engine APIs in Spotify terms and provides sensible defaults. Engineers simply specify how many instances of what role they want and where. SPM ensures that number of instances will exist, using Google’s instance groups behind the scenes. Pools can be grown or shrunk at will.
SPM is a stateless Pyramid service, relying primarily on Sid and the Google Cloud Platform to do the heavy lifting. While Sid has a standalone web interface we’re tightly integrating SPM with Spotify’s internal microservice management dashboard.
Physical Pools
Spotify won’t be rid of physical machines in the immediate future, so we’ve built pool support into Sid’s backend. While Sid’s provisioning request model has served us well, it can encourage too much attachment to individual machines. Having engineers manage their physical machine capacity similarly to Google’s instance groups will introduce them to paradigms like automatic replacement of failed machines and randomised hostnames as we transition to GCP. Sid’s pool support allows SPM to manage both Google Compute instances and physical machines, with the same user experience regardless of backend.
Summary
In the last few years Spotify’s machine management infrastructure has been a great example of the merits of iterative development. As a small squad of Site Reliability and Backend Engineers we’ve been able to significantly improve the productivity of our colleagues by building just enough automation to free ourselves to iterate. We’ve reduced the turnaround time for new machines from weeks to minutes, and drastically reduced the amount of support interactions required to manage machines at Spotify.




